3줄 요약
1. CLIP의 CLS token이 anomal vs normal로 align 되어있지 않다.
2. CLIP은 classification 기반의 prompt로 학습 되었기에, AD prompt에서는 성능을 내지 못한다.
3. object agnostic prompt learning을 통해 위 문제를 해결한다.
abstract
- ZSAD를 위해 vlm, clip등을 사용하려 할 때 cls token으로 anomaly feature를 추출하려 시도하면 이미지 test-alignment가 깨짐, 왜? -> 기본적으로 CLIP을 예로 들자면 CLIP은 classification을 전제로 만들어짐, cls 토큰이 anomaly vs normal 이렇게 맞춰져 있지 않음.
- 또한 domain shift로 인한 성능 저하가 존재하는데 AD은 one-class detection이다.(detect는 여러개지만, 하나의 클래스에 여러개의 defect가 존재한다.) 하지만 CLIP은 multi-class 기반으로 만들어졌다.
-> object agnostic text prompt를 통해서 위 문제를 해결한다.

introduction
- 기존에 존재하는 prompt learning은 global feature랑 prompt의 alignment를 맞추는 방향에 집중한다. fig1 참조.
Anomaly clip : object-agnostic-prompt-learning
- 이로 인해 localization 성능이 떨어진다. 직관적으로 미세한, 작은 defect의 탐지 성능이 떨어진다고 해석해도 무방하다 생각한다.
- 또한 상당한 predifne manual prompt에 의존하는 것 또한 문제인데, winclip의 예시에서도 엄청난 manual prompt가 존재한다.
-> object augnostic prompt embedding을 통해 matual prompt의 의존성을 없앤다.
NOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARNING

object agnostic text prompt design
- 기존의 "A photo of [cls]" prompt는 object sementic informtion을 전제로 만듦.
- 하지만 저 프롬프트에는 normal or anomal의 정보를 담고있지 않다.
- "A photo of [sufix : broken] [cls]" 이렇게 하면 anomal vs normal의 정보를 담을 수 있다. -> 그.러.나 predefine manual prompt에 크게 의존한다.
- 또한 이렇게 사용해도 기존 클립은 multi-class-classification 기반이기에 alignment가 틀어짐.
- 또한 이렇게 manual prompt의 문제가 있는데, 세상에 존재하는 수많은 defect를 전부 정의하지 않으면, manual prompt에 존재하지 않는 defect는 오히려 찾지 못할 수 있다.
-> A photo of [bottle] 이렇게 하지 말고 A photo of [object]와 같이 object agnostic prompt design을 사용하자.
learning generic abnormality and normality prompt
glocal context optimization
- learnable prompt를 학습 시키는데, 기존 연구에서는 global feature과의 alignment에 집중한 반면, local feature & global feature alignment를 만족시키게 학습하자.
- global feature alignment : cls token과 prompt의 alignment(cls token이 global한 anomaly value를 가지고 있게 만드는 방법은 refinement of local visual space에서 설명)
- local feature alignment : clip의 intermidiate feature와 prompt embedding의 alignment
refinement of the textual space
- 위 사진을 참고.
- 핵심은 learnable prompt ventor를 사용한다는 것이다.
- 텍스트 인코더에 forward path에 learnable prompt를 concat한다.
- 예를 들어 (10,768)벡터에 learnable vector (2,768)을 concat -> (12, 768) -> forward path
- 다음 레이어에서는 12,768에서 이전에 붙인 learnable vector를 제거하고 다시 새로운 벡터를 붙인다.
-> 그냥 한 번만 learnable vector를 붙이지 왜 계속 붙였다 제거했다 반복? -> 기존 clip의 text space를 보존하기 위해서.
-> 어쩌피 해당 learnable vector는 인코더를 돌면서 기존의 10,768 벡터에 조금씩 반영되고 back propa 과정에서 학습에 관여한다.
-> 해당 벡터를 제거하지 않고 계속 사용하면, 급격한 인코더 출력 변화로 인해 text space가 뒤틀린다.
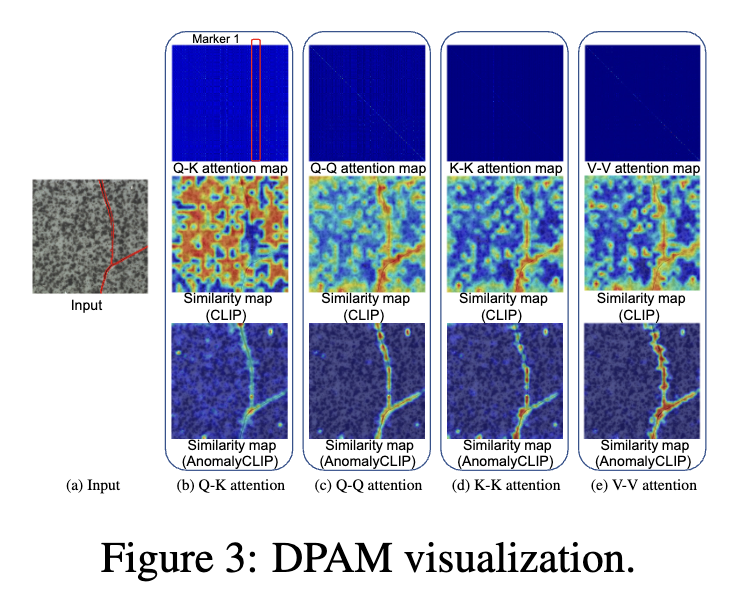
refinement of local visual space
- 결론은 V-V attention을 사용하자. vvattention은 경량화 및 local feature embedding 성능이 좋다. fig3. 참조
- 왜 vv attention이 local feature embdding 성능이 좋냐고 물어보면 나는 아래와 같이 대답할거다.
1. 실험을 해보니 좋더라.
2. Q,K,V는 각각의 linear layer를 독립적으로 사용하는데, 이는 각 피처를 추상화시킨다 생각한다. 따라서 VV attention은 하나의 layer만 사용하기에 이전 feature의 불필요한 추상화를 제거한다.
experiment
experiment setup
- MVtec부터 medical 까지 총 17개를 사용함.
implementation detail
- VIT-L/14@336px
main result
ZSAD performance on diverse medical dataset


can we obtain better ZSAD performance if fine tuned using medical image data?
- 세밀한 segmentation이 필요한 곳에서 winclip을 압도함.

object-agnostic vs object-aware prompt learning


