3줄 요약
1. manual prompt가 pretrained clip과 맞지 않는다. learnable prompt를 사용하자.
2. 전부 다 learnable prompt로 쓰지 말고, learnable-suffix-prompt를 사용해서 matual-normal prompt와 잘 조합하면, 알아서 최적의 anomal prompt가 만들어지게 하자.
3. prompt학습의 수렴을 2단계로 나눠서 하자.
a. 일단 정상 이미지랑 정상 prompt alignment를 맞추자.
b. 그리고 정상 이미지와 이상치 프롬프트를 L2 loss사용해서 최대한 멀리 떨어뜨려놓는다.
- 해당 과정을 거치게 되면 프롬프트 alignment가 맞춰진다.
논문 다 읽고 궁금점 : 아니 그럼 normal manual prompt는 최적의 prompt인가? 왜 suffix만 learnable prompt로 두는 것인가. 개인적인 생각으로는 전부 learnable prompt로 등록하면 학습 수렴이 엄청 힘들기에 manual prompt로 학습 bias를 만드는 것이라 생각함.
abstract
- 기존의 CLIP기반 anomaly detection에서 prompt의 alignment가 잘 맞지 않않다.
- clip은 기본적으로 multi-class 환경을 전제로 만들어졌다.
- winclip같은 경우는 이런 alignment를 맞추기 위해 prompt ensemble을 활용했다.
- multi-class의 classification에서 one-class AD로 domain-shift로 인한 성능 저하가 발생했다.

introduction
- winclip과 같은 prompt ensemble은 성은의 한계가 있다.
- prompt를 trainable parameter로 등록하여 최적의 프롬프트를 학습하게 하자.
- clip은 학습할 때 anomal, normal과 같은 쿼리를 학습하지 않는다. 이미지와 클래스 프롬프트를 학습한다. 이에 쿼리로 "normal 또는 anomal"을 입력하여 임베딩 했을 때 해당 임베딩 벡터가 최적의 alignment라고 말할 수 없다.
preliminaries
clip and prompt learning
- contrastive learning을 할 때 prompt를 trainable parameter로 등록하여 파라미터도 학습 가능하게 하자.
- <model(정상 이미지), (정상 프롬프트 또는 이상치 프롬프트)> : "정상 이미지"만 사용해서 clip을 훈련한다.
- 왜 정상 이미지만 사용? -> 현실에서 anoamal이미지를 충분히 구하는 게 어렵기에 정상 이미지만 있는 시나리오를 사용했다고 함.
- 여기서의 목적은 정상 이미지랑 정상 프롬프트는 최대한 가깝게, 정상 이미지랑 이상치 프롬프트랑은 그냥 just 멀리 떨어지게 학습한다.
- 아니 그럼 이상치 프롬프트는 learnable prompt로도 구성되어있는데 아무데나 임베딩 되어도 된다는거냐? 라는 질문이 있을 수 있지만, 그건 clip learning 끝나고, explicit anomaly margin을 통해 해결한다.
clip surgery
- Q, ,K ,V attention을 활용한 vit의 CLS token은 localization 성능이 떨어진다.
- VIT 백본을 학습할 때 CLS token은 말 그대로 이미지의 클래스를 나타낸다. 이미지 전체를 표현하는 능력은 좋지만, localization 능력은 떨어진다.
- 또한 Q K V는 각각 attention 전 linear layer를 독립적으로 사용한다. 이를 vv attention(value-value)으로 바꾸면 모델의 복잡도 또한 적어진다.
- V-V attention : 기존 attention은 Q, K, V가 각각 다른 linear layer를 사용함. 즉 원래의 feature가 추상화 됨. 하지만 VVattention은 하나를 공유함. 즉 입력 그대로의 feature를 사용하기에 원본 피처가 추상화 되지 않고 localization 성능이 좋음.
- 한마디로 줄이면, 불필요한 추상화를 줄여 localization 성능에 집중함.
methodology
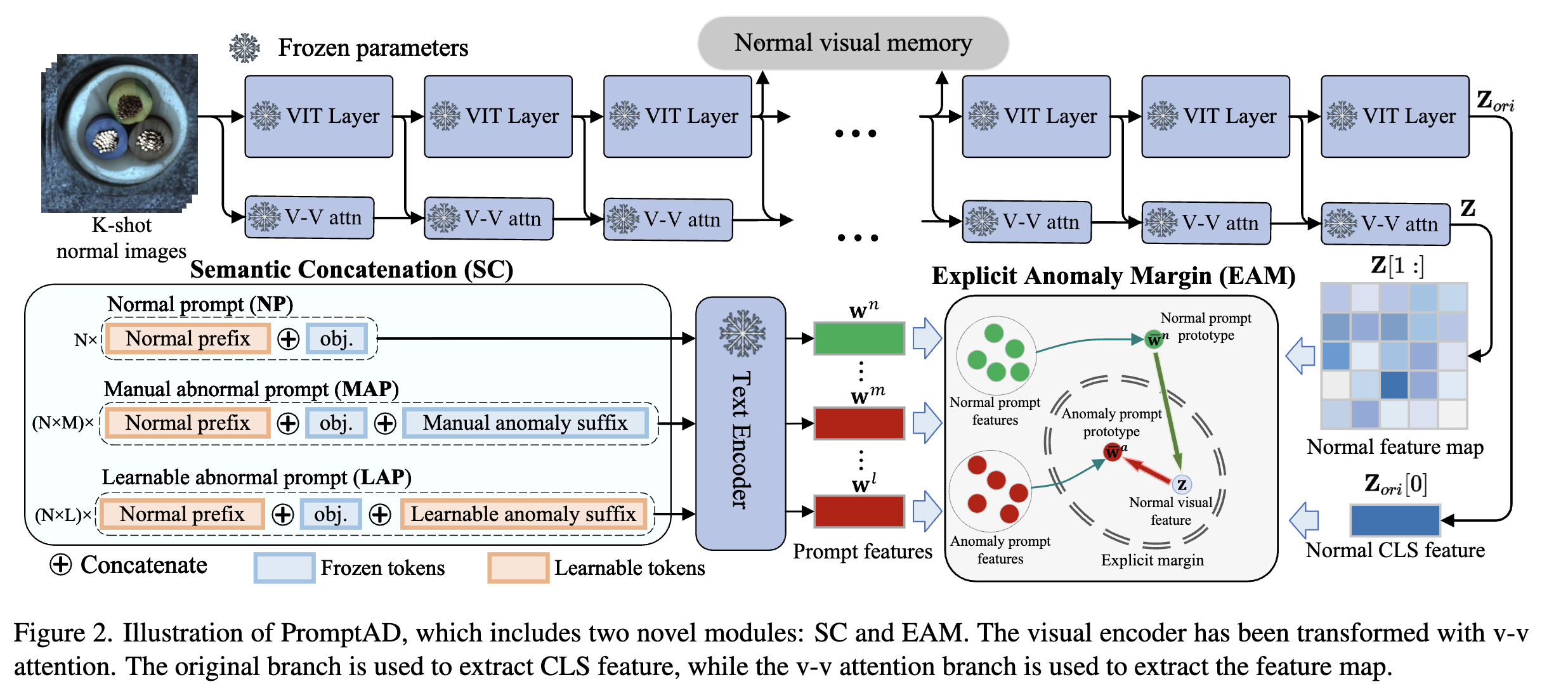
overview
- N개의 normal prefix가 있음. ex) "사과 사진"
- M개의 manual anomal suffix가 있음 "썩은" -> 이건 괘 learnable prompt로 등록 안 시킴? -> 전부 학습 가능한 파라미터로 등록하면, 수렴의 어려움 있음. 일종의 학습 bias를 만듦.
- L개의 leanable anomal suffix가 있음 "뭉개진"
- normal prompt를 만들 땐 N을 사용하고, anomal prompt를 만들 땐 N*M, N*L을 사용함. ex) "썩은" + "사과 사진"
semantic concatenation
- introduction에서 말한것과 동일하게 clip을 훈련시킨다.
- semantic concatenation은 정상 프롬프트에 적절한 suffix를 붙이면 anomal로 표현할 수 있다는 것이다.
explicit anomaly margin
- clip을 훈련하게 되면 [정상 이미지, 정상 프롬프트] alignment가 맞춰진다.
- 이 상황에서 정상 프롬프트와 비정상 프롬프트를 최대한 멀리 떨어뜨려놓는다. L2 loss를 사용한다. (L2loss는 유클리디언 거리니까..)
anomaly detection
- 1. 이후 vv-attention으로 local feature를 잘 임베딩 한 cls token과 유사도를 통해 anomaly점수를 활용하고,
- 2. feature map으로는 segmentation을 사용한다.
experiment
data
- MVTec full, VISA full
evaluation metrics
- AUROC
implementation detail
- LION-400M based clip with vit-B/16+
pixel-level, image-level, compare with other few-shot



