3줄 요약
- 의료 관련 데이터에서 CLIP을 사용할 때 domain shift로 인한 성능 저하를 없애기 위해 한정된 데이터에서 domain adaptation을 진행하는 PathCLIP을 소개한다.
- alpha factor를 이용하여 동적으로 back bone CLIP의 사전 지식 반영 정도를 조정한다.
- SimCLR의 loss에 아이디어를 얻어, 강한 augmentation을 적용한 이미지와 약한 augmentation을 적용한 이미지를 pair로 만들어 contrastive loss에 추가한다.
Limitation of Previous Studies
높은 수준의 의학 데이터를 얻고 어노테이팅 하는 과정을 시간이 매우 소모되는 작업이다. 이런 대용량의 데이터를 얻기 어렵기 때문에 의료 도메인에서는 fine-tune을 진행하는 방향으로 vision task가 발전해왔다.
그러나 여전히 fine-tune에도 많은 데이터가 필요하고 (문제점 1), backbone이 훈련된 데이터와 매우 다른 의료 데이터로 인해 domain gap으로 인해 성능 저하가 발생한다.(문제점 2)
이에 논문 저자는 다음과 같이 생각했다. -> 어떻게 적은 데이터로 모델이 효과적으로 다른 도메인에 적응할 수 있을까?
manual prompt
- CLIP은 manual prompt에 의존한다. 또한 해당 프롬프트에서 하나의 단어만 바뀌어도 전혀 다른 prompt embedding을 생성한다. 또한 domain이 다른 생황에서 prompt를 수정했을 때 그것이 vision vector랑 align 되어있다는 보장을 할 수 없다. 그렇다고 prompt를 수정하면, domain gap으로 인해 성능이 매우 떨어진다.
- CoCoOp의 방법을 생각할 수 있다. (부연 설명 CoCoOP : FiLM의 방식으로 vision embedding vector를 text embedding을 만들 때 추가하는 것. Q-former의 decoder model 예와 비슷한 모양새) 하지만 CoCoOp는 많은 컴퓨팅 자원을 소모한다.
practical fine-tuning
- 사실 해당 도메인에서 CLIP back bone이 훈련된 만큼의 데이터가 있고 무한대의 컴퓨팅 파워와 모델의 학습을 기다릴 시간이 있으면 domain gap을 해결된다. 하지만 이것은 현실적으로 불가능하다.
- 모델을 adaptation 하는데 큰 데이터에 의존한다면 실용적이지 못한 방법일 것이다.
Observations & Motivations

정리하자면, 많은 양의 어노테이트 데이터를 구하기도 어렵고, 모델을 scratch로 학습하기에도 제약이 있으니 적은 데이터로 효과적으로 fine-tuning 시키고 싶다는 것이다. 하지만, CLIP을 fine-tuning 시키는 데 두가지 문제점이 있다.
overfitting
- 400M dataset에서 훈련된 CLIP을 직접 적은 데이터를 사용하여 downstream task에 적용하면 오버피팅이 발생한다.
- 해결 방법 1 : hidden representation perturbation:
- 해결 방법 2 : Dual-view vision contrastive
catastrophic forgetting
- catastrophic forgetting은 CLIP이 downstream domain의 지식에도 능통하지 못하면서 기존 지식도 잊어버리는 문제를 뜻한다.
- 해결 방법 : residual feature refinement : 저 비용으로 CLIP의 이미지 vector를 adapt 하는 역할을 한다. 해당 모듈은 제부적인 피처의 패턴을 이미지로부터 추출하는 역할을 한다.
- RFR 모듈을 적은 데이터로도 기존 CLIP의 성능을 유지하며 특정 데이터에 잘 적응하도록 조정하는 역할을 한다.
Method

- 원본 피처에 가우시안 노이즈를 추가한다.
- TFT module은 adaptor layer인데 해당 레이어에서 1024 -> 512 -> 256 -> 512 -> 1024로 linear transform 시킨다.
- a라는 factor만큼 해당 피처를 반영해서 원본 피쳐랑 concat 한다.
- 이후 prompt와의 코사인 유사도를 통해 classification을 진행하고 contrastive loss에 의해 튜닝된다.
Language-Vision Pre-training
CLIP 학습에 대한 overview이다. CLIP은 이미지 text pair를 이용하여 contrastive learning을 진행한다. positive pair는 CosSim을 최대화 하는 방향으로, negative pair은 CosSim을 최소화 하는 방향으로 학습한다. 모델 학습이 vision이나 text 모델 한 쪽으로 쏠리는 것을 방지하기 위해 image to text, text to image 이렇게 2개의 평균을 내어서 학습한다. 코드에서는 image to text의 transpose를 text to image로 사용한다.

inference에서는 그냥 간단하게 필자의 주관을 바탕으로 논문을 재 해석하여 설명하자면 다음과 같다. 이미지 하나와 prompt 여러개를 준비하여 afinity 행렬을 구하고 softmax를 적용하여 classification을 진행한다.
Residual Feature Refinement
직접 vision transformer를 fine-tuning시키기에는 앞서 말한 overfitting, catastrophic forgetting 때문에 불가능했다.
RFR module을 통해 sub-feature을 만들고 original feature에 concat 하는 방식으로 즉, adaptor module을 학습하는 방식으로 fine tuning 된다.

오케이 직접 훈련하면 기존 성능이 훼손된다는 건 알겠는데 왜? 그 이유가 뭘까?
논문에서도 나오고 필자도 논문의 말에 동의하는데 그 내용은 다음과 같다.
기존에 훈련된 weight는 finetuning 과정에서 마치 weight initialize와 같이 작용한다. 그러면 fine tuning에서 그 weight가 변형되고, 결과적으로 모델의 출력이 span 하는 벡터스페이스가 완전히 깨지게 되는 것이다.
따라서 다음의 방식으로 튜닝한다.
- 원본 피처에 가우시안 노이즈를 추가한다.
- TFT module은 adaptor layer인데 해당 레이어에서 1024 -> 512 -> 256 -> 512 -> 1024로 linear transform 시킨다.
- a라는 factor만큼 해당 피처를 반영해서 원본 피쳐(original)랑 concat 한다.
- 이후 prompt와의 코사인 유사도를 통해 classification을 진행하고 contrastive loss에 의해 튜닝된다.
- 이떄 adapter layer를 제외한 모든 layer는 frozen 된다.
Self-adaptive residual ratio

Residual Feature Refinement에서 alpha factor를 소개했었다. 실험적으로, alpha 값이 너무 크면 underfitting, 너무 작으면 overfitting이 발생
하였다. 따라서 alpha 값을 적절히 조절하는 게 매우 중요했다. 해당 논문에서는 모델이 스스로 alpha 값을 조절하게 설계하였다.

DVC: Dual-view Vision Contrastive : 강한 augmentation을 적용한 이미지와 약한 augmentation을 적용한 이미지가 같은 임베딩 벡터를 생성하는지 확인하는 작업을 한다. 해당 결과를 나타내는 수식은 "타우"로 나타내며 alpha factor를 결정하는데 쓰인다. 해당 factor의 자세한 쓰임세는 위 사진에 정리되어 있다.
Path-CLIP: End-to-end adaptation of CLIP to pathology tasks
기존의 CLIP loss의 변형을 사용하는데 이는 SimCLR에서 인사이트를 얻었다고 한다.
핵심은 강한 augmentation을 진행한 이미지와 약한 augmentation을 적용한 이미지가 같은 vision vector를 형성해야 한다는 것이다.
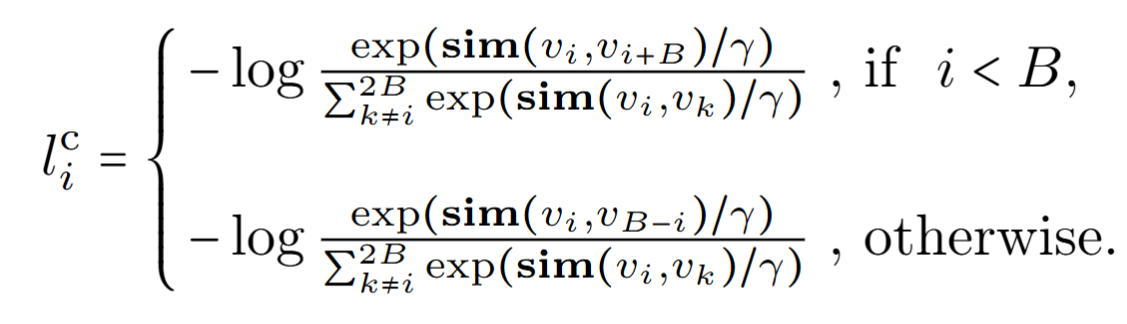
기존 CLIP의 loss와 합쳐져 전체 loss는 다음과 같다.

Experiments
Datasets : PCam, MHIST
back bone : vision-resnet50, text-BERT
Quantitative comparison on PCam

적을 데이터를 활용했을 때 다른 모델에 비해 좋은 모습을 보이나 MixMatch와 FlexMatch에는 밀리는 모습이다.
Pros & Cons
Pros
- 정말 간단하고 적은 데이터로도 overfitting, underfitting, forget 현상을 피하면서 의학 데이터로의 adaptation을 가능케 한다.
Cons
- 데이터가 충분한 상황에서 supervised에 밀리는 모습을 보인다.