2025 논문들을 보면 Q-former를 사용한다. 특히 vision-text alignment를 맞추는데 사용하는 것 같다. anomaly-ov를 읽는데 q-former 부분이 도저히 이해가 안가서 해당 논문을 읽으려 한다.
논문을 읽은 후 한 줄로 Q-former를 정리하면 다음과 같다. : 이미지 feature에서 LLM이 이해할 수 있게 중요한 벡터들만 추출한다.
목차는 다음과 같다.
Abstract
1. introduction
2. related work
3. method
3.1 model architecture
3.2 Bootstrap Vision-Language Representation Learning from a Frozen Image Encode
- Image-Text Contrastive Learning
- Image-grounded Text Generation
- Image-Text Matching
3.3. Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
3.4. Model Pre-training
- Pre-training data
- Pre-trained image encoder and LLM
- Pre-training settings
4. Experiment
4.1. Instructed Zero-shot Image-to-Text Generation
4.2. Image Captioning
4.3. Visual Question Answering
4.4. Image-Text Retrieval
5. Limitation
Abstract
- BLIP2 를 제안함. BLIP2는 frozen vlm을 기반으로 bootstrap 시킴.
- BLIP2의 핵심은 Q-former를 이용한 모달리티 갭을 줄이는 것임.
- 2단계의 stage로 BLIP2는 훈련됨.
- 1. image encoder를 frozen 시키고 vlm의 representation learning
- 2. text encoder를 frozen 시키고 vlm의 generative learning
1. introduction

- VLM을 만들 때 각각의 unimodal을 pretrain 시키는 과정은 컴퓨팅 파워와 시간이 매우 오래 소모되는 작업이다. 이 때문에 pretrained 된 image text unimodal을 사용하여, VLM을 구성하기를 원한다.
- 하지만 두 unimodal을 붙였을 때 두 모델 간 modality gap이 맞지 않는다. 즉, cross modal alignment가 맞지 않는다.
- Q-former를 사용하여 unimodal을 활용한 VLM의 cross modal alignment를 맞추는 것을 제안함.
- Q-former는 2 개의 stage로 훈련함.
- stage1 : Q-former가 텍스트랑 잘 어울리는 visual representation vector를 추출하는 과정을 학습
- stage2 : Q-former가 LLM이 이해하게끔 결과를 출력하는 과정을 학습.
2. related work
- VLP의 핵심은 두 모델의 contrastive learning이다.
- 이전 연구들 중 가장 대중적으로 사용하는 방법은 end to end 방식이다.
- 이는 처음부터 모델을 학습시키는 것이다. 이러한 방법은 이미 pretrained 된 unimodal을 활용하기 어려울 뿐 아니라 높은 컴퓨팅 파워가 소모된다.
- 최근 들어서는 LLM을 frozen 시키고 image encoder를 학습시키는 방식이 사용되는데 이 또한 image encoder를 학습 시키는 과정에서 컴퓨팅 자원이 소모된다.
- 다른 방식으로는 이미지 인코더를 finetunes 시키는 방식인데, 이는 이미지 인코더의 출력을 LLM에 연결에는 방식으로 진행된다.
- 결론적으로 unimodal의 학습이 진행되며, 이는 높은 컴퓨팅 자원을 소모하게 된다.
3. method
- Q-former를 이용하여 pretrained LLM, image encoder의 cross-modal alignment를 맞춘다.
- 저세한 구현은 다음을 참고. https://github.com/salesforce/LAVIS/blob/main/lavis/models/blip2_models/blip2_qformer.py
LAVIS/lavis/models/blip2_models/blip2_qformer.py at main · salesforce/LAVIS
LAVIS - A One-stop Library for Language-Vision Intelligence - salesforce/LAVIS
github.com
3.1 model architecture
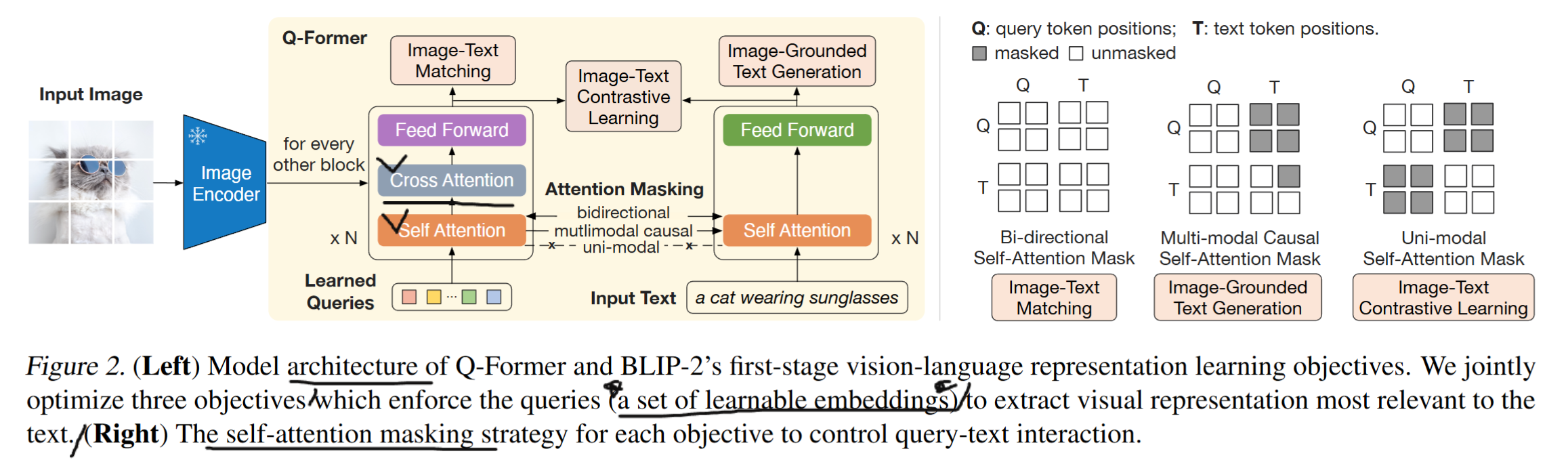
- Q-former는 홀수 짝수 번갈아가면서 layer가 구성된다. 홀수번째는 image transformer, 짝수번째는 text transformer 이런식으로 구성되며, 병렬 구성이 아니다. FFN또한 공유한다.
- 1. image transformer : frozen image encoder에서 최적의 feature를 뽑아낸다.
- 2. text transformer : text 인코더와 decoder의 역할을 수행한다.
- 쿼리는 32개의 쿼리가 있고, 차원은 768이다.
- 3개의 mask가 존재한다. 이는 하나의 self attention layer를 공유하기 때문에 목적에 맞는 mask가 필요하다.
- bi-directional : 쿼리랑 텍스트에 mask를 하지 않는다.
- multimodal : 쿼리가 텍스트의 어떤 weighted sum으로 표현되는지를 제한한다.
- uni-modal : cross weighted sum을 제한한다.
- Q-former는 3개의 objective function을 가지고 있다. (가지고 있다는 표현이 어색하지만, 논문의 억양을 최대한 녹임.) 이에 대한 자세한 설명은 3.2에 있다.
3.2 Bootstrap Vision-Language Representation Learning from a Frozen Image Encode
- Image-Text Contrastive Learning
- text-sub block의 cls token과 image sub-block들의 contrastive learning을 진행한다.
- 일단 learnable query랑 이미지 인코더 출력과 attention을 한다는 것의 의미는 필자가 생각하기에, 쿼리를 이미지 벡터의 weighted sum으로 표현한다는 것이다. 즉, 이미지의 중요한 부분만 골라서 쿼리 set을 구성한다는 것이다.
- Contrastive learning의 의의는 쿼리가 이미지 피처에서 weighted sim으로 추출한 정보가 텍스트와 얼마나 잘 정렬되는지를 학습하여, 이미지-텍스트 쌍의 유사성을 최적화하는 데 있다고 생각한다.
- Image-grounded Text Generation
- query랑 image랑 cross attention을 진행하고 다음 레이어에서 다시 서로 self attention을 하게 된다.
- 그러면 다음과 같은 상황이 발생된다.
- 1. query는 이미지 벡터의 weighted sum으로 표현된다.
- 2. text vector는 이전까지 들어온 text vector와 이미지 벡터의 어떤 weighted sum으로 표현되는지 확인하게 된다.
- 3. 즉, 지금까지 들어온 텍스트와 이미지를 기반으로 다음 토큰은 어떤걸 출력해야 하는지를 학습한다
- Image-Text Matching
- 해당 과정은 간단하게 positive, negative image-text-pair matching을 확인한다.
3.3. Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
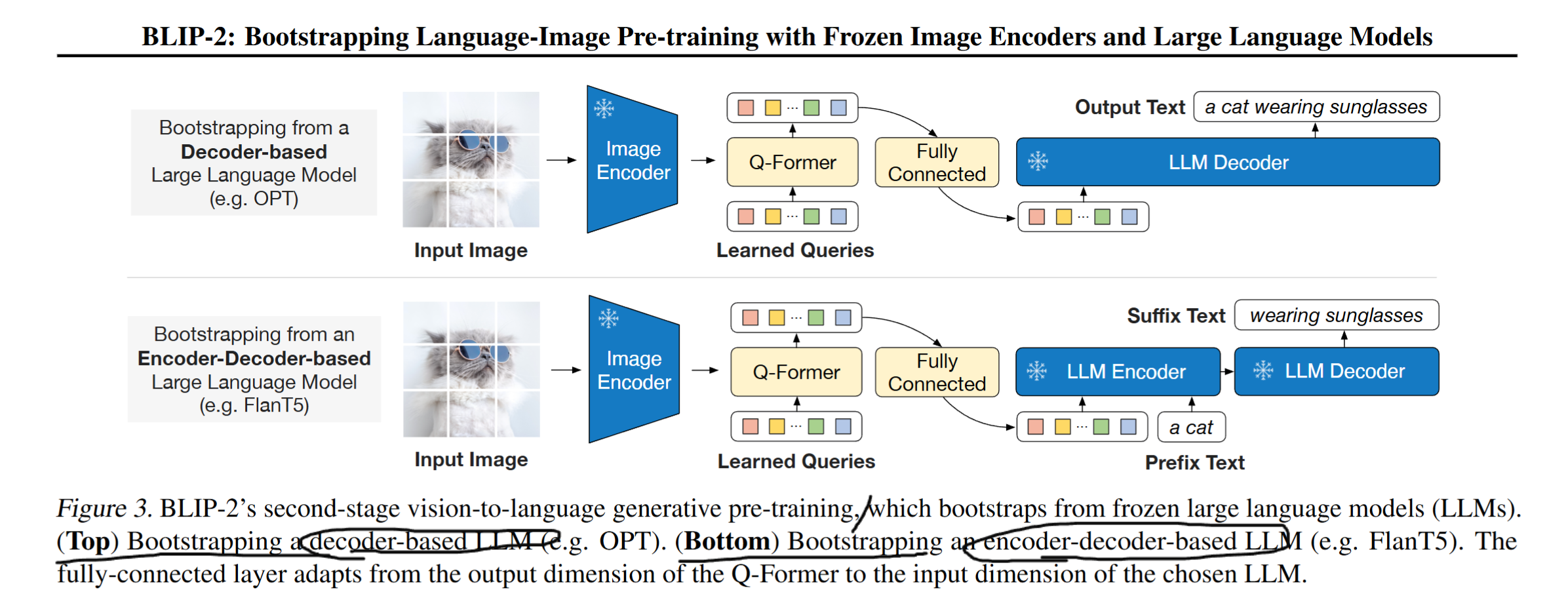
- 이제 Q-former의 Z(32,768 = 출력)가 LLM에 붙어서 사진의 정보를 추가하는 역할을 한다.
3.4. Model Pre-training
- Pre-training data : COCO, Visual Genome, CC3M, CC12M, SBU, LAION400M을 사용한다.
- Pre-trained image encoder and LLM : 이미지 인코더는 VIT-L/14 from CLIP, ViT-g/14 from EVA-CLIP을 사용한다. LLM은 OPT를 사용한다.
- Pre-training settings : 컴퓨터 사양과 LR 관련하여 말해주는데 해당 부분은 기술하지 않겠다.
4. Experiment

5. Limitation
- few-shot VQA의 개선이 없음. 데이터 가체가 1:1 pair로 구성되어있기에 이미지 하나와 샘플 text 몇 개를 줘도 발전이 없음.
- Image1: [cat image] Question: What is this? Answer: A cat.
Image2: [dog image] Question: What is this? Answer: A dog.
Image3: [new image] Question: What is this? Answer: ? - 위와 같은 예시를 줘도, 구조적으로 1:1 pair만 학습하게끔 설계됨.
- frozen LLM이기에 부정확한 지식까지 모두 상속받음. 이미지의 핵심 요소가 아닌 배경에 대한 설명을 할 때가 있음.