읽기 전 : 뭔가 normal-abnormal alignment가 잘 맞춰져 있는 것 모델을 제안하는 것 같다. 아니면 auxiliary데이터를 활용해서 뭔가를 하나보다~

위 사진을 보면 기존 클립 기반의 IAD의 문제를 말해준다.
논문을 볼 떄 마다 들었던 의문은 다음과 같다. 왜 image의 feature level 벡터가 normal-abnormal alignment가 맞춰져 있다고 가정하고 시작하지? classification 기반으로 학습을 했을거고 그러면 image level의 feature를 one class segmentation이나 binary classification에 사용하면 domain shift로 인한 문제가 있을 것 같은데 뭐 결과가 잘 나오니 그냥 그렇구나~ 내가 뭔가 잘 모르는 게 있구나~ 하고 넘겼다. 근데 위 사진을 보면서 아 진짜 그런 문제가 있었구나 라는 것을 느꼈다.
3줄 요약
- original clip은 normal-abnormal의 alignment가 약하게 이루어져 있다.
- 이는 vision part를 개선해도 clip의 text encoder에 의존하면, sub-optimal한 성능을 제공한다.
- 2-stage adaptation을 통해 alignment를 강화한다.
AA-CLIP : Enhancing zero-shot anomaly detection via anomaly-aware CLIP
abstract
- 기존의 CLIP기반 IAD에는 Anomaly unawareness 문제가 있음. 생각해보면 당연함, CLIP은 다중클래스 분류로 학습했고. 이상치 라는 클래스는 학습한 적이 없음.
- 2단계의 adaptation method로 anomaly aware 하면서 효율적인 CLIP을 제안함. 2단계는 다음과 같음.
- 1. text anchor(텍스트 쿼리) 기반으로 normal abnormal alignment를 맞춘다.
- 2. text anchor 기반으로 feature level의 image-text alignment를 맞춘다.
introduction

- figure1.left를 보면 CLIP을 그대로 사용하면 normal abnormal alignment가 맞지 않는다.
- 추가적으로 개괄적으로 나오지만, 텍스트 임베딩이 오브젝트레벨의 defect를 대표할 수 있는지 실험해보니 그렇지 않음을 발견했다. 이는 figure1.left와 같은 맥락이라 생각한다.
- 2단계의 adaptation 과정을 통해서 generalization 성능을 유지하면서 IAD의 성능을 올릴 수 있었다.
- 위 사진을 보면 text space alignment문제를 바로 알 수 있다. 근데 보면 Alignclip이랑 말하는 바가 비슷하다. Alignclip에서는 clip이 상대적 거리를 기준으로 학습하기에 dense한 vector set을 형성한다고 지적한다. 보면 original clip의 결과가 나오려면, dense한 text vector set이 생겨야 한다. 결국 두 논문은 비슷한 문제를 다른 방식으로 푼다고 생각한다. 하나는 inductive bias를 높이면서 joint space에 임베딩하고 하나는 adaptation을 진행하고..
related work
- CLIP-based IAD

- CLIP based IAD는 기본적으로 clip text encoder에 의존한다. vision feature extraction성능을 개선해도, 여전히 clip text encoder의 협업을 통해 IAD를 진행하고, 이는 sub-optimal한 결과를 제공하게 된다.
- 그럼 learnable prompt method를 사용하면 되지 않는가? 라고 말하기 쉽지만, 이는 clip의 text embedding space를 손상시킬 수 있기에 조심해야 한다.
method
- problem formulation
- ZSAD에서는 train에서 보지 못한 unseen class에 대한 one-class-classification을 진행한다.
- Segmentation의 경우에는 one-class-classification의 확장된 형태인 binary mask를 생성하는 방법으로 테스트 된다.
- current challenges
- Anomaly unawareness in clip

- 일반적으로 vision feature와 normal-abnormal pair text embedding vector를 통해 코사인 유사도를 보고 abnormal벡터와 유사도가 높으면, 이상치라 판단한다.
- 하지만, clip에서는 normal-abnormal쿼리가 약하게 align되어있고, 이는 vision defect가 존재함에도 불구하고 normal text와 코사인 유사도가 높은 상황이 발생하였다.
- 기본적으로 오리지널 CLIP이 학습될 때는 정상적인 이미지를 기반으로 학습했을 것이다. 텍스트 또한 그러하다. 그렇기에 abnormal vs normal에 대한 가이드라인이 부족한 상황이다.
- embedding Adaptation dilemma
- 이미 충분히 학습된 CLIP을 추가로 학습 시키면 오버피팅의 위험이 있다. 이는 unseen class에 대한 성능을 훼손할 수 있다.
- overview of our solution
- residual adaptation layer가 transformer block에 들어간다.
- 2단계로 학습을 진행하는데, text embedding을 학습하고 text 관련 모델은 froze 시킨다.
- 이후에는 vision model을 학습시킨다.
- AA-CLIP with Two-stage Adaptation strategy

- residual adapter
- 간한하게 Linear layer를 통해 구성되었다.
- two-stage training strategy
- distangling anomaly-aware text anchors
- 순서대로 그냥 학습이랑 별 다를게 없다. 코사인 유사도 보고~ 그걸로 object level classification 하고~ segmentation loss 구하고~ text vector pair의 코릴레이션이 0으로 가게, 그러니까 normal vs abnormal이 완전히 구분되게 학습한다.



- Aligning patch features according to text anchors
- 그냥 피처 aggregation 해서 patch level CosSim을 본다. 해당 부분의 학습은 한 블럭으로 끝난다 디테일한 세팅은 나오지 않는다.

Experiment
- setup
- data : MVTec AD, VisA, BTAD, MPDD, BMAD, CVC-ClinicDB, CVC-ColonDB, KvasirSEG, CVC-300
중요!! VISA에서 학습했는데 2, 4, 8, 16, full shot으로 번갈아가면서 학습함. 그리고 normal abnormal ratio는 1:1로 맞춤
- metric : AUROC
- comparison with SOTA methods

- clip, winclip은 non-train이기 때문에 ZSAD라도 불공평하고, full-shot에서 거의 대부분의 데이터에서 SOTA를 당성했다.
- 2~16shot은 아직 Anchor가 적절하게 학습되지 않은 것 같다.
- visualization
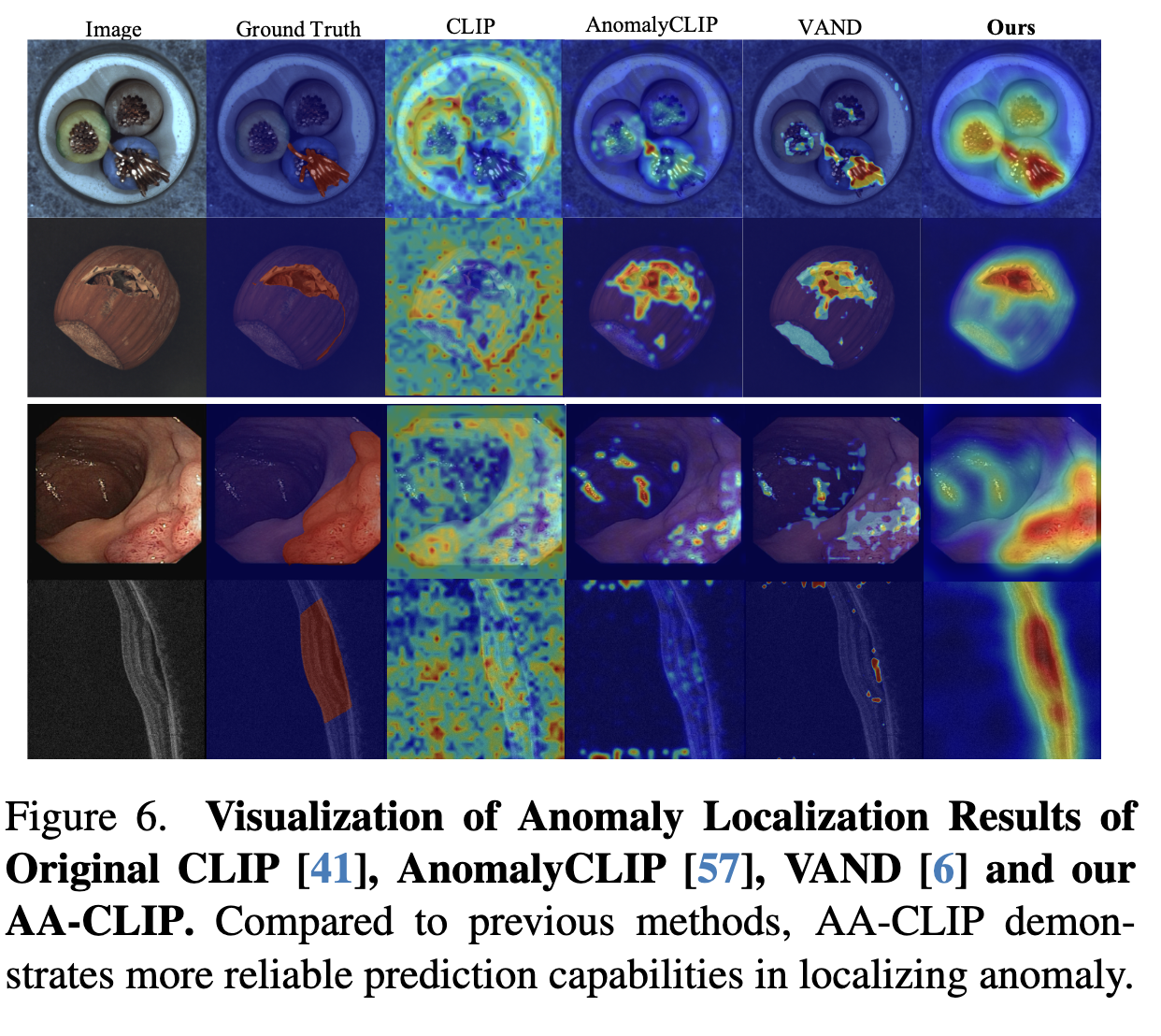
- AA-CLIP demonstrates fewer false-negative predictions in both industrial and medical domains라고 나와있다.
- 정말 내가 계속 원했던 그 대답이다. FN은 훨씬 치명적인데 그 FN을 획기적으로 감소시켰다.
conclusion
- experiment에서 full-shot train할 때 오버피팅 징후를 포착했다고 함. 이는 추가적인 학습 최적화를 시사함.
- 그럼에도 불구하고 CLIP pretrain 모델에서 normal abnormal에 대한 '뉘양스'를 녹이며 제로샷 성능을 끌어 올리는데 큰 기여를 함.

총평 : 정말 재밌다. 복잡한 메서드, 프롬프트를 사용하지 않으면서 효과적으로 타파함.