
논문읽기
Dinomaly: The Less Is More Philosophy in Multi-Class Unsupervised Anomaly Detection
언시
2025. 5. 30. 21:53

논문을 읽은 후 소감 : 상당히 간단한 방법으로 UAD를 향상시켰지만, 여전히 zero-shot/few-shot과 같이 데이터가 부족한 시나리오에 대해서는 부족함.
3줄 요약
- multi-class UAD와 one-class UAD의 성능 GAP을 줄인다.
- reconstruction based UAD를 진행하는데, abnormal 이미지를 normal 이미지로 재구성 하는 것을 효율적으로 학습시키기 위해 bottel neck(MLP)에 drop out을 적용한다.
- '약한' 재구성을 위해 pixel to pixel로 reconstruction 될 것 같은 부분은 학습을 막는다.
abstract
- 하나의 클래스에 맞춤으로 모델을 학습하는 방법은 여전히 다중 클래스 모델보다 높은 점수를 보인다.
- 다중 클래스 모델을 개선하여, 두 method의 점수 gap을 줄인다.
- 이를 개선할 방법은 4가지 이다.
- 1. scalable transformer
- 2. dropout
- 3. linear attention
- 4. loose reconstruction
- 논문에서는 위 4가지 방법이 다중 클래스 모델을 개선할 수 있는 방법이라 제시한다. 근거는 observation&method에서 제시한다.
Observations & Motivations
- 논문에서는 UAD, MUAD의 성능 차이가 극심하다는 것을 설명한다.
- 논문에서 표기한 UAD는 one-class-one-model 방식이다. 하나의 클래스에 맞춤으로 모델을 제작하는 것이다.
- 하지만, one-class-one-model은 너무 비효율 적이다.
- MUAD가 실제 산업 시나리오에 더 fit하지만, 성능의 차이가 극심하다.
- UAD의 핵심은 identity mapping을 피하는 것이다.
- UAD 특히 논문에서 제시하는 방식은 abnormal image를 normal image로 재구성하고 이를 쿼리 이미지와 비교하여 AD를 진행하는 것이다.
- 이에 identity mapping; 너무 '잘' reconstruct 시키게 되면 AD를 진행할 수 없게 된다.
- 이에 논문에서는 abstract에서 말한 3가지 방법으로 identity mapping을 피하면서 MUAD의 성능을 높이는 방법을 제시한다.
Method
1. encoder : 8개의 transformer block
2. decoder : 8개의 transformer block
3. '느슨한' reconstruction을 통해 anomaly detection을 수행한다.
+(필자의 주관이 들어간 설명)
MLP의 dropout :
- 기존의 reconstruction 기반의 AD는 다음과 같다. 정상 이미지를 autoencoder 형식으로 복원하는 과정을 훈련한다. 만약 이미지에 defect가 있다면, 모델은 어전히 normal 이미지를 reconstruct 할 것이다. 모델이 만든 이미지와 원본 이미지의 차이가 AD score에 해당한다.
- 그러나 해당 과정을 저 원활하게 수행하기 위해서 처음부터 defect가 있는 이미지를 정상 이미지로 복원하는 과정을 학습한다면, 아마 더 좋은 성능이 나올 것이다.
- 그러나 이를 위해서는 직접 defect dataset에 접근하거나 사람이 손으로 defect 이미지를 구현해야 한다. 이는 unsupervised AD에 부합하지 못하는 방법일 것이다.
- 이를 모델 내부에서 처리하는 방식이 있다. 바로 Dropout이다. 모델 내부에서 dropout을 적절히 적용한다면, 마치 결함이 있는 이미지를 정상 이미지로 재구성 하는 방식처럼 학습이 될 것이다.
Unfocused Linear Attention
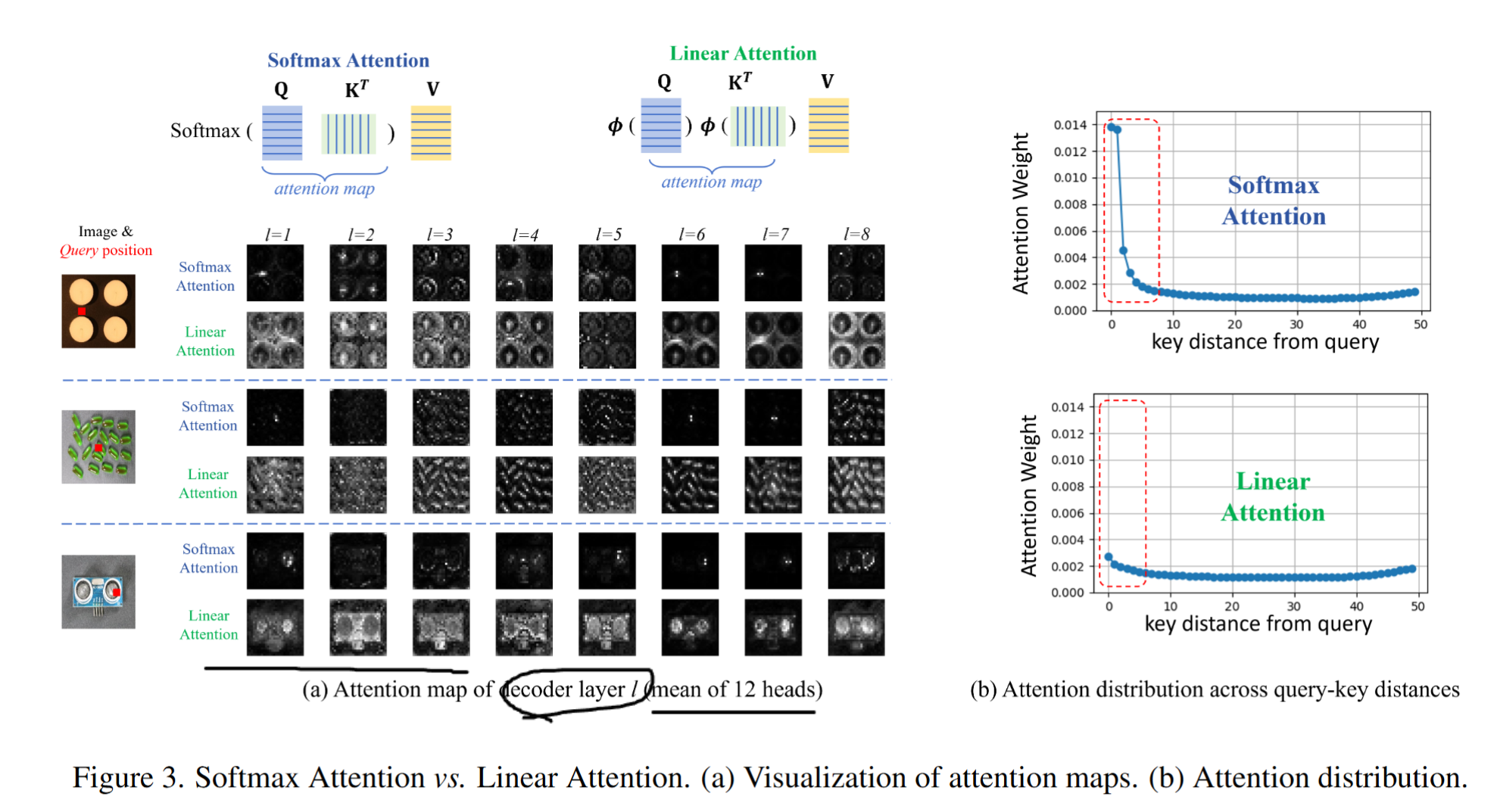
- reconstruct AD의 핵심은 너무 잘 reconstruct 하면 안된다는 것이다.
- 1:1, pixel to pixel로 모든 것을 다 reconstruct 하면 AD를 진행할 수 없다.
- softmax attention은 쿼리가 키의 어떤 weighted sum으로 표현되는지 전부 상세하게 계산한다.
- 하지만 linear attention은 전부 좀 균등하게 weight를 배분한다.
- 즉 너무 foreground에만 집중하지 않는다는 것이다.
- 이게 reconstruct에서 원하는 것 아닌가? defect는 reconstruct 하지 말고 전체적인 foreground의 느낌을 reconstruct 하는 것! 그렇다 이런 이유로 linear attention을 사용한다.
loose reconstruction
해당 부분은 로스에 대한 설명이다. 이 부분은 전체적인 흐름과 함께 사진으로 설명한다.
Experiments
훈련에 특별한 세팅은 없고 그냥 UAD 세팅이다. 와 그런데 성능이 정말 좋은 것을 볼 수 있다.
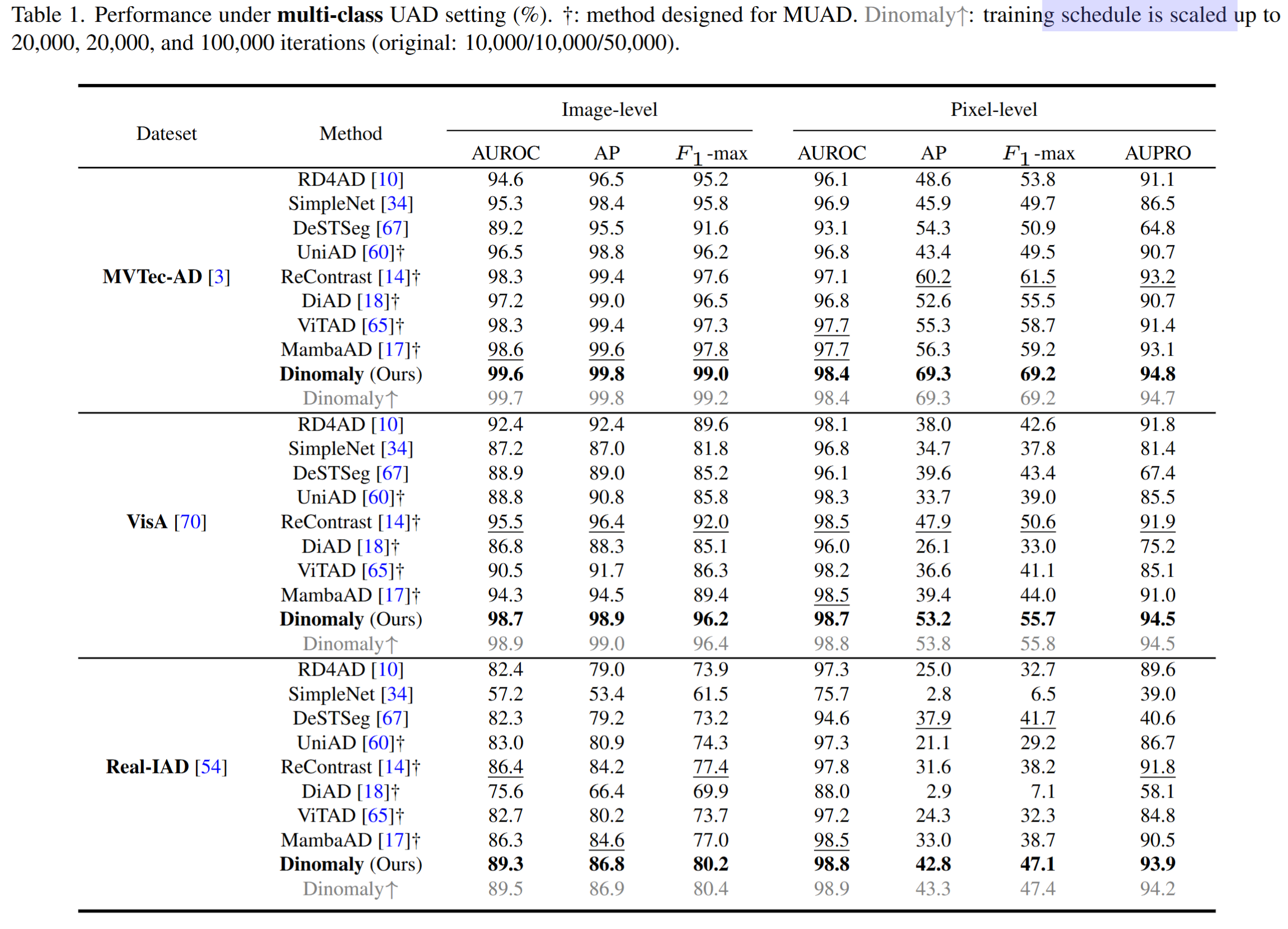
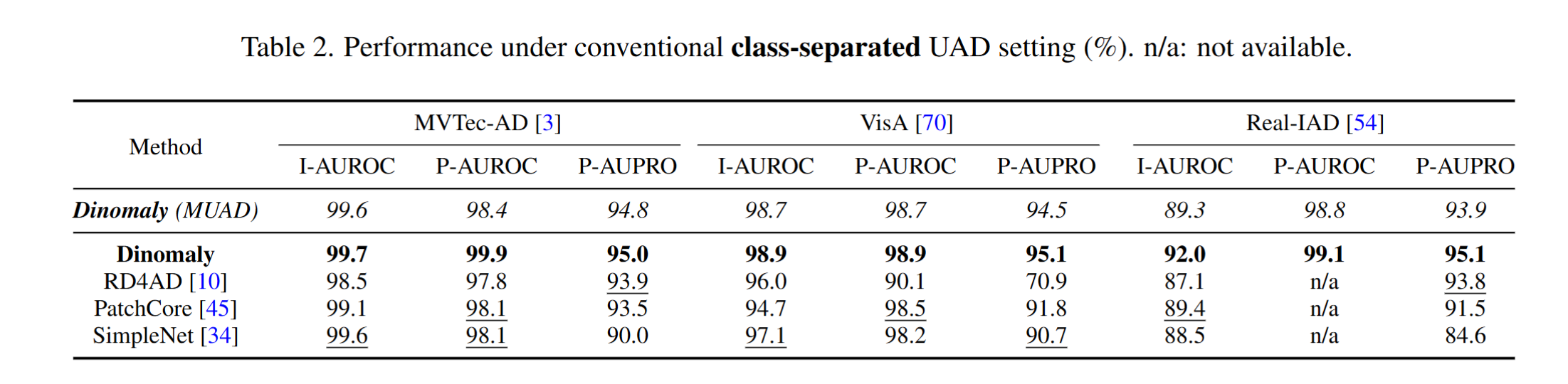
Pros & Cons
Pros
- 정말 간단한 방법 특히 dropout으로 노이즈를 추가하는 기법으로 높은 UAD 성능을 내었다.
- one-class UAD method와 multi class UAD의 성능 GAP을 줄이고 거의 뛰어 넘었다.
Cons
- reconstruction based AD 무조건 언급되는 단점이 있다. 바로 '데이터를 너무 많이 사용한다' 이다.
- 또한 zero-shot 문제에서 자유로울 수 없다.