
Adapting Visual-Language Models forGeneralizable Anomaly Detection in Medical Images
3줄 요약
- lightweight adaptation을 위해 multi level residual adapter를 visual encoder에 추가한다.
- 기존 CLIP의 feature에 adaptor feature가 concat 되는 형태인데, path-clip과 다른 점은 concat ratio가 0.1로 고정이다.
- real-world에서 사용될 때는 zero-shot, few-shot 결과 모두를 사용하여 정확도를 높인다.
Limitation of Previous Studies
요약 : 기존의 adaptation for AD는 의료 데이터에 적용하지 않고 만들어졌다. 이에 의료 도메인에서의 adaptation for AD를 연구한다.
medical anomaly detection은 잘못된 진단을 방지하고, 의료진의 조기 개입을 위해 병리학적 이상을 찾아내는 것이 목적이다.
의료 이상치 탐지에서는 다양한 병리학 데이터에 다재다능한 모델이 필요하다.
이에 few-shot 기반 모델들이 연구되었고, 이는 여러 병리학 데이터에서 나름 괜찮은 성능을 보였다.
그러나 모델을 데이터에 맞춰 다시 훈련시키는 등 unseen data에 대한 부가적인 조치를 필요로 했다.
CLIP을 이용한 few-shot anomalt detection method는 manual prompt를 이용하여 CLIP을 직접 adopt 시키는 방식을 사용했었다. 해당 방법에서 발전한 방식은 prompt vector를 vision vector의 joint space에 임베딩 시키는 방식이었다. 해당 문장을 읽고 바로 생각난 논문은 CoCoOp, VCP-CLIP 정도가 있다. 다른 비슷한 방식으로는 align clip 정도가 있을 것 같다.
그러나 기존의 방식은 의료도메인이 아닌 다른 도메인에서 연구되었다.
이에 본 논문에서는 의료 데이터를 활용한 domain adaptation for AD를 제안한다.
Observations & Motivations
CLIP을 medical AD에 정용하기 위해서는 두 가지 문제점이 있다.
1. 의료 도메인으로 적절히 모델이 적응 해야한다.
원본 CLIP은 이미지의 sementic information을 감지하는 역할을 했지만, AD에서의 CLIP은 sementic irregularities를 감지해야 한다.
2. domain gap을 최소화 해야한다.

이에, multi layer vision adaptor를 통해 pre-trained CLIP을 medical domain으로 adaptation을 진행한다.
Method
train에서 데이터는 (원본 이미지, 클래스, 세그멘테이션 마스크)로 구성된다. 클래스와 세그멘테이션 마스크는 (-, +)로 인코딩 되어있다.
- : normal
+ : anomal
test 시나리오는 2가지 이다.
1. zero-shot
2. few-shot {2, 4, 8, 16}
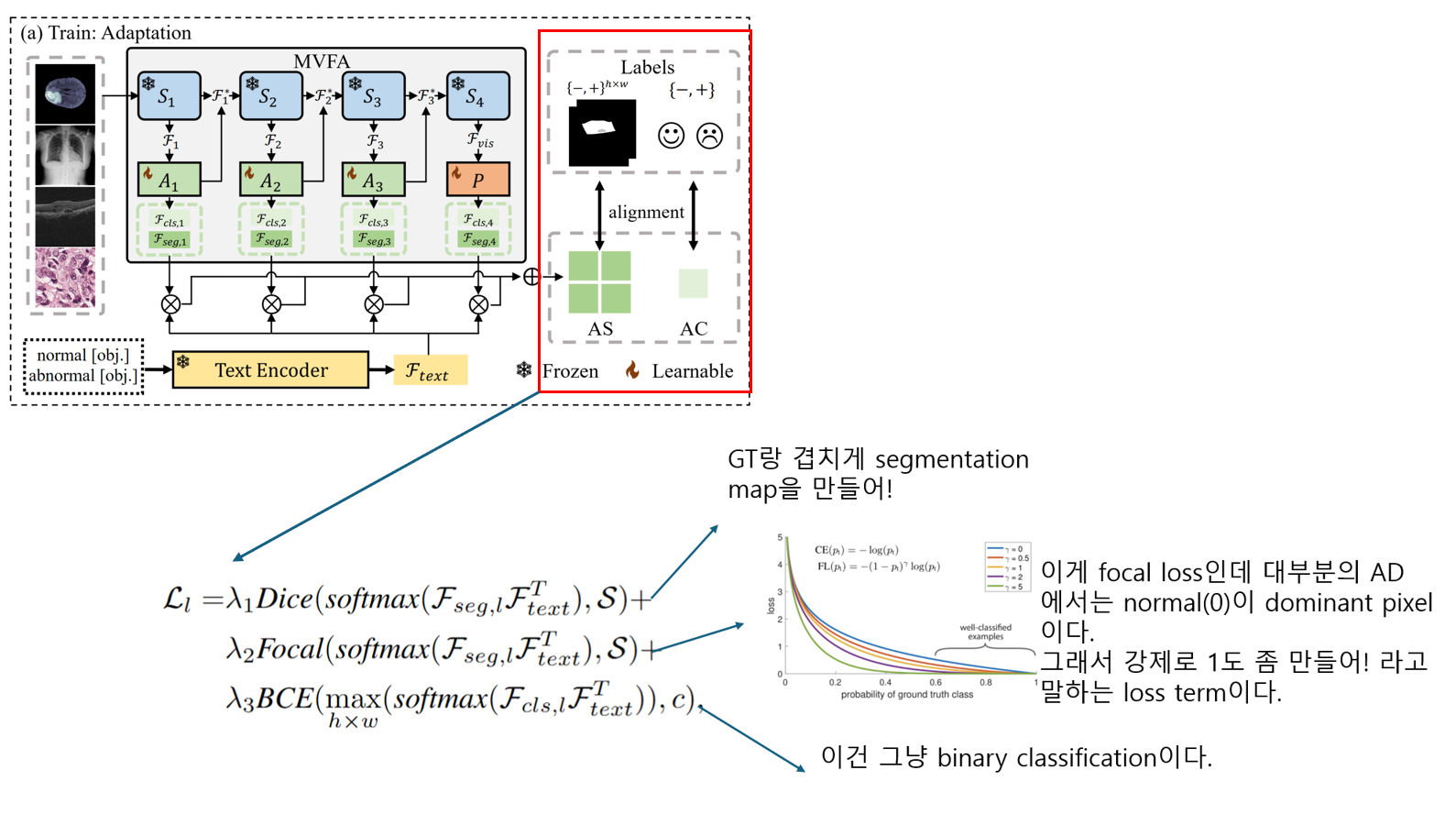
Train: Multi-Level Feature Adaptation
Multi-level Visual Feature Adapter (MVFA) : resnet처럼 원본 비전 피처에 붙는 방식이다. 이러한 방식을 사용했을 때 overfitting이 덜 발생한다.
1. Linear -> ReLU -> Linear 구조로 되어있는 adaptor가 감마 factor 만큼 기존 클립의 feature에 붙는다.
2. F_cls, F_seg는 각각의 linear layer를 사용한다.
3. F_cls 와 F_seg는 text와 코사인 유사도를 측정하게 된다. 이 때 text vector는 winclip의 prompt ensemble과 같이 여러 프롬프트의 평균을 내어 normal/abnormal prompt를 만든다. 구체적인 프롬프트는 공개하지 않았다.
전체 loss에 대한 설명은 다음과 같다.
Test: Multi-Level Feature Comparison

특이사항으로는 모델을 few/zero-shot 상황에서 평가하는 게 아닌 일반적인 모델의 출력을 확인하고 싶을 땐 zero-shot과 few-shot의 출력 모두를 사용한다.
Experiments
dataset : brain MRI, liver CT, retinal OCT, chest X-ray, digital histopathology included in BMAD
훈련에는 train(with label) 데이터를 사용함. K = {2, 4, 8, 16} 중 random 하게 선택 함(훈련 데이터 shot ).

few-shot

zero-shot
projector vs both(projector+adapter)

visualization results

Pros & Cons
Pros
- 모델의 일반적인 출력을 기대할 때 zero-shot + few-shot 결과를 합쳐서 사용하는 것이 인상적이다.(주관)
- medical domain으로 adapter를 통해 image level 뿐 아니라 pixel level로 adaptation 시켰다.
Cons
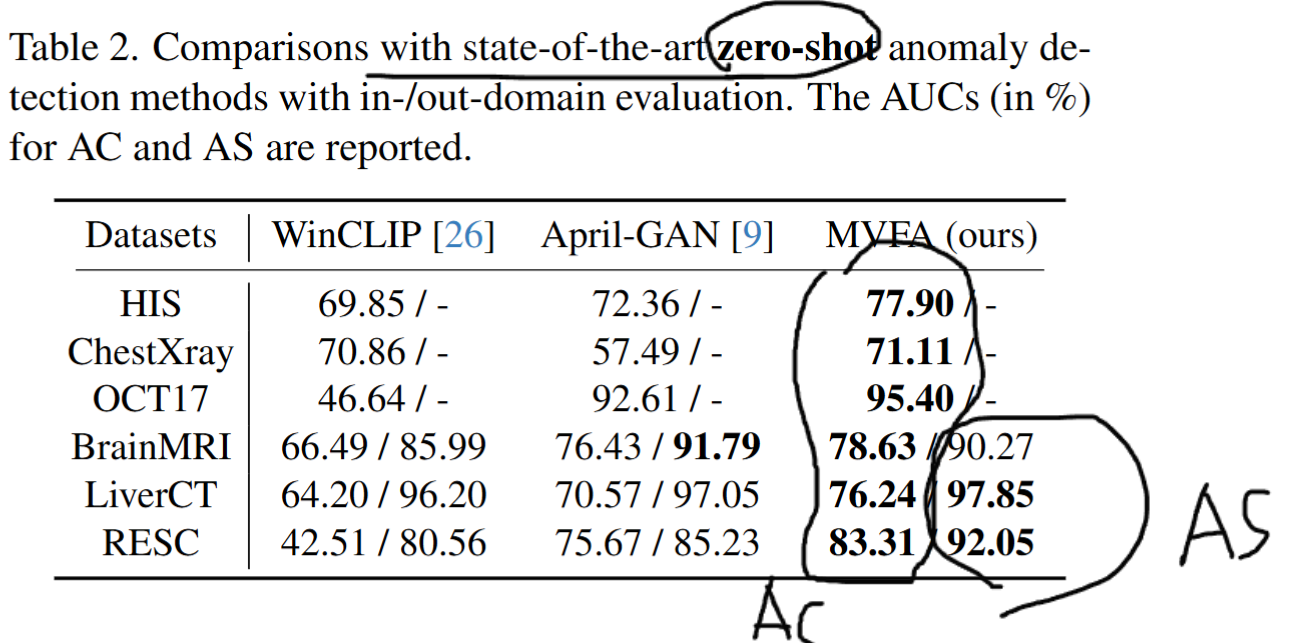
- chestXray에서는 MEDclip에게 AC 점수가 밀리는 모습을 보였고, OCT17데이터 에서는 april-gan에서 밀리는 모습을 보였다.