논문읽기
Mitigate the Gap: Improving Cross-Modal Alignment in CLIP
띠오니의 IAD
2025. 4. 19. 23:04
3줄 요약
- 기존 clip은 이미지-텍스트 임베딩 벡터가 dense하고 떨어져 있어, 공유 레이어로 joint space에 임베딩한다.
- 변형된 nce loss를 통해 텍스트-이미지 alignment를 강화, 평균 코사인 유사도를 높인다.
- fine-tuning 성능 저하 문제를 해결, cc3m 데이터 플롯으로 gap 감소 효과를 직관적으로 확인할 수 있다.
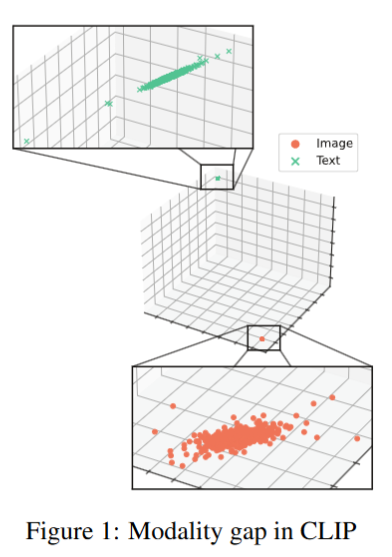
Limitation of Previous Studies
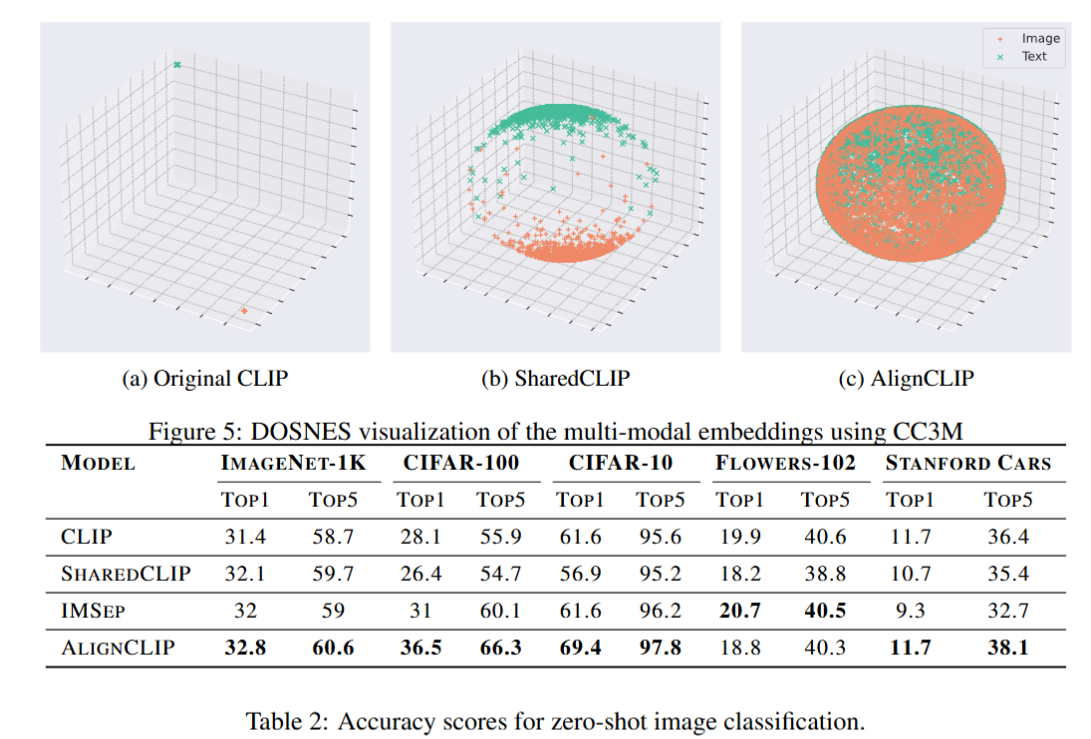
- 기존 clip의 이미지-텍스트 임베딩 벡터는 dense하고 seperated 상태로, down stream task에서 모델이 두 벡터 간 상관관계를 효과적으로 포착하지 못한다. (그림 1 참조)
- clip은 상대 거리만을 기준으로 학습해, pair 벡터가 다른 벡터보다 약간 더 유사하기만 하면 된다. 이로 인해 이미지 텍스트 간 거리(gap)가 존재하고, cross modality가 부족해 벡터가 dense하고 seperated 상태로 남는다.
- 이전 연구들은 이미지 벡터를 텍스트 벡터로 옮기는 방식으로 gap을 줄이려 했다. 같은 카테고리의 이미지-텍스트 벡터 평균 거리를 objective로 삼아 거리를 최소화했으나, down stream task에서 심각한 성능 저하가 발생했다.
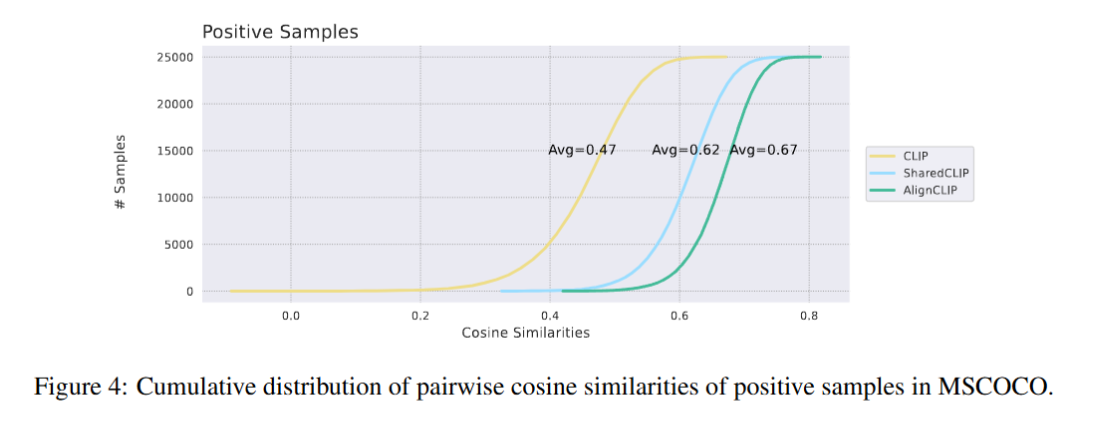
- cc3m 데이터 플롯에서 알 수 있듯, clip의 학습 방식은 벡터를 상대적으로만 떨어뜨려 평균 코사인 유사도가 낮아, 모델 성능에 한계가 있다.
Motivations & Ideas
- 이미지-텍스트 임베딩 벡터가 dense하고 seperated 상태인 modality gap을 줄여야 down stream task에서 성능을 높일 수 있다. gap이 크면 모델이 이미지-텍스트 pair의 상관관계를 제대로 포착하지 못한다.
- 기존 clip은 상대 거리 학습으로 평균 코사인 유사도가 낮다. 공유 레이어를 통해 이미지 인코더와 텍스트 인코더가 동일한 파라미터 공간을 사용하면 joint space에 더 잘 임베딩될 것이다.
- nce loss를 변형해 이미지-텍스트 pair의 유사도를 높이고, intra-modality separation으로 비슷한 카테고리 이미지는 근처에, 다른 카테고리는 멀리 배치해 alignment를 강화하자.
- cc3m 데이터 플롯에서 gap이 줄어든 모습을 직관적으로 확인할 수 있으며, fine-tuning 성능 저하 문제를 해결할 수 있다.
Method
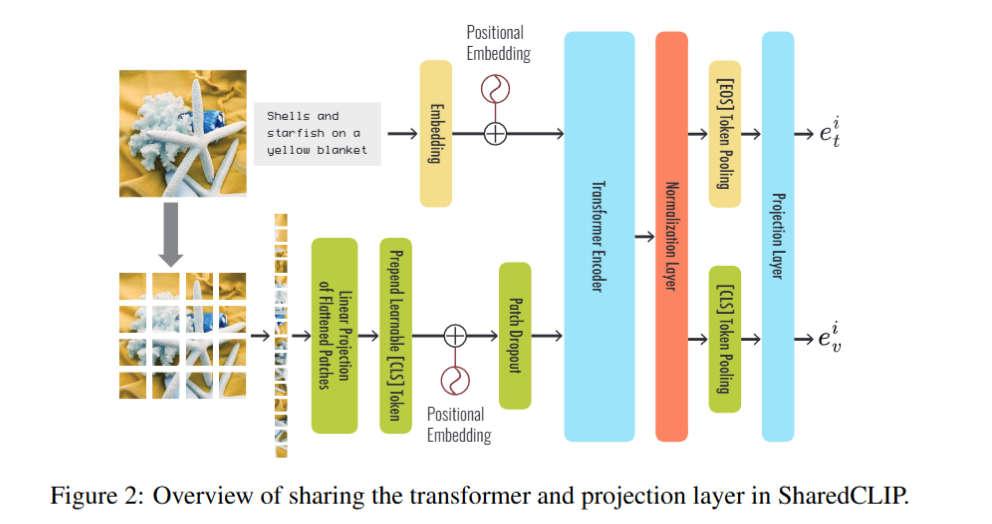
Architecture (Overall Framework)
- Sharing the Learnable Parameter Space in CLIP:
- 이미지 인코더와 텍스트 인코더가 backbone의 learnable parameter를 공유한다.
- 공유 레이어를 통해 모델의 inductive bias가 높아져 이미지와 텍스트가 joint space에 효과적으로 임베딩된다.
- cc3m 데이터 플롯에서 확인되듯, 공유 레이어는 벡터 간 gap을 줄이고 alignment를 강화한다.
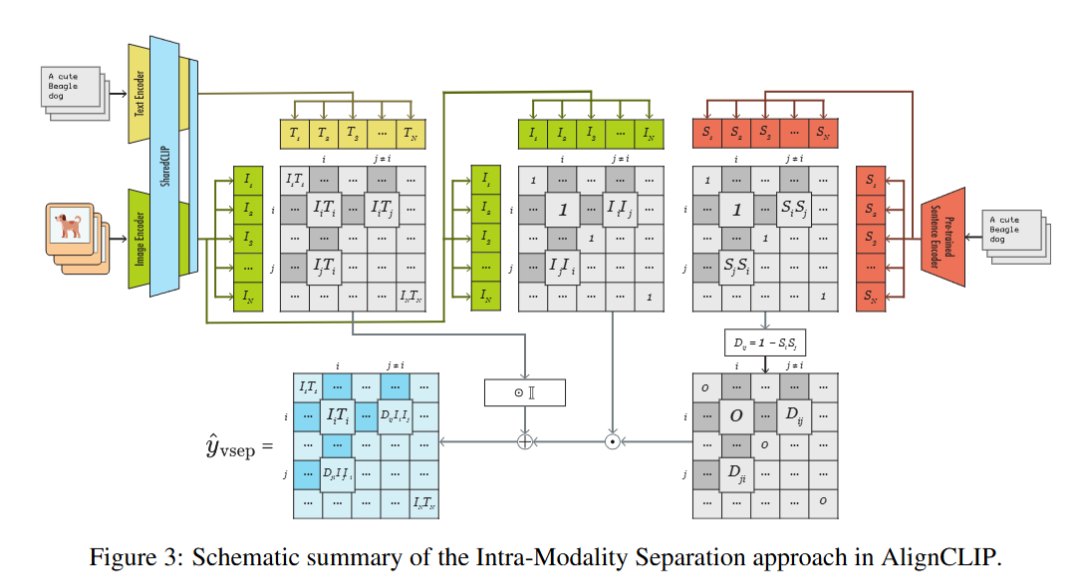
- Intra-Modality Separation:
- 비슷한 카테고리의 이미지는 임베딩 공간에서 근처에 배치하고, 다른 카테고리는 멀리 떨어뜨린다.
- 이미지-텍스트 pair는 최대한 가깝게 유지해 cross modality를 높인다.
- 이 방식은 이미지 간 구조적 분리와 텍스트-이미지 유사도를 동시에 최적화한다.
- Modified NCE Loss:
- 기존 clip의 nce loss를 변형해 이미지-텍스트 pair의 코사인 유사도를 직접적으로 높인다.
- 상대 거리뿐 아니라 절대적인 alignment를 강화해 dense하고 seperated 상태를 완화한다.
Training (or Fine-tuning)
- 이미지 인코더와 텍스트 인코더가 공유 레이어를 사용해 joint space에서 학습한다.
- modified nce loss로 이미지-텍스트 pair의 유사도를 최적화, intra-modality separation을 통해 카테고리별 이미지 분포를 조정한다.
- cc3m 데이터셋으로 훈련, fine-tuning 시 down stream task 성능 저하를 방지하도록 loss를 설계.(이미지넷 등등 여러 데이터에서 classification을 학습한다.)
- 학습 파라미터 디테일은 공개되지 않았으나, 변형된 loss는 수렴이 어려울 수 있어 최적화가 중요하다.
Inference
- 입력 이미지와 텍스트를 공유 레이어 기반 인코더로 임베딩, joint space에서 유사도 계산.
- intra-modality separation으로 카테고리별 이미지 분포가 명확해, 이미지-텍스트 pair 매칭이 정확하다.
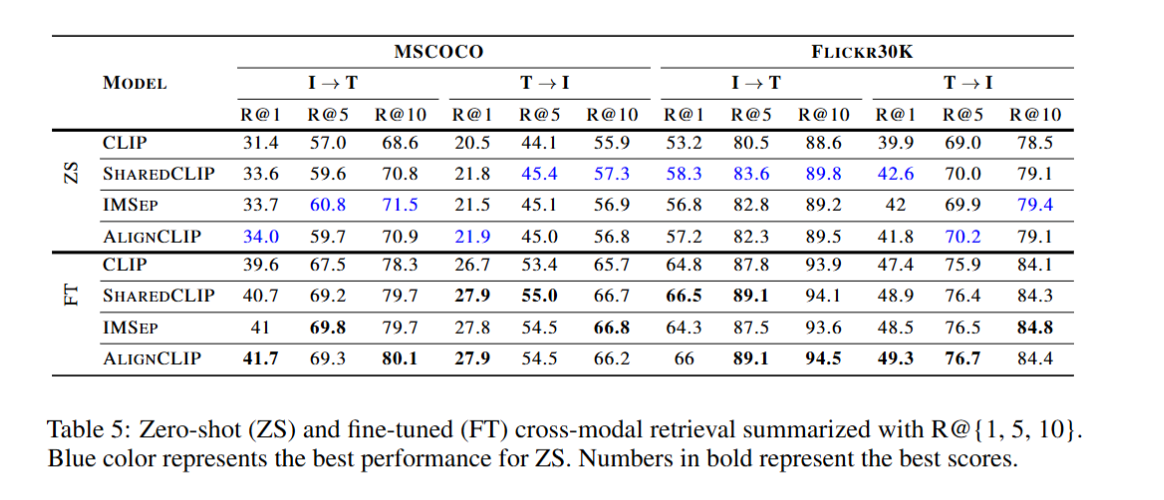
- zero-shot은 약간 성능이 밀릴 수 있으나, fine-tuning 시 top-5 recall(r@5)에서 기존 clip 대비 우수한 성능 확인.
- cc3m 플롯(fig 5)에서 벡터 간 gap이 줄어든 모습이 직관적으로 드러난다.
Experiments → Results
- Dataset: cc3m 데이터셋으로 임베딩 벡터 플롯 및 성능 평가.
- Metrics: image-to-text(i→t) top-5 recall(r@5), image-level/pixel-level auroc.
- Implementation: clip 기반, 공유 레이어와 변형된 nce loss 적용.
- Results:
- table 5: i→t r@5에서 zero-shot은 기존 clip에 비해 약간 밀리지만, fine-tuning 시 성능이 크게 향상. down stream task 성능 저하 문제를 개선함.
- fig 5: cc3m 데이터셋의 임베딩 벡터 플롯에서 gap 감소와 joint space alignment를 명확히 보임.
- intra modality separation으로 카테고리별 이미지 분포가 명확, cross modality 강화로 pair 유사도 향상.
Pros & Cons
Pros
- 공유 레이어와 변형된 nce loss로 cross modality를 높여 joint space에 안정적으로 임베딩한다.
- 기존 clip의 fine-tuning 성능 저하 문제를 해결, down stream task에서 우수한 성능 확인.
- cc3m 플롯(fig 5)으로 gap 감소 효과를 직관적으로 보여, alignment 개선 명확.
Cons
- fig 5 플롯이 차원 축소로 극단적으로 보일 수 있다. 768차원 실제 공간에서는 벡터 간 거리가 더 벌어질 가능성 있다.
- 변형된 nce loss의 수렴이 어려워 보이며, 학습 파라미터 디테일 미공개로 최적화 과정이 불명확하다.