VCP-CLIP: A visual context prompting modelfor zero-shot anomaly segmentation
읽기 전 : 진짜 prompting 논문만 3연속이다. anomaly clip만 봐도 AD task에서 feature text alignment가 핵심인 것 같다.
3줄 요약
1. 기존 learnable prompt 텍스트 인코더에서만 학습되었다. cross modal interaction을 사용하자.
2. text-encode, vision encode를 독립적으로 진행하지 말고, text encode과정에서 vision encode의 영향을 받게 하자.
3. 그러면, 이미지의 특징을 잘 담은 prompt가 만들어질 것이다.
+추가.
어떤 state pair를 사용했는지는 중요하지 않음, 훈련에서는 good/damaged를 사용했지만, 추가 test에서 normal/abnormal pair를 사용했는데 성능 차이가 거의 없음. 이에 대한 설명은 페이지 마지막에서 설명함.
abstract
- 기존 ZSAD에서는 "painstakingly crafted test prompt"를 사용하는 문제가 있다. 즉 manual prompt 문제가 있다.
- 또한 manual peompt를 만들 때 어떤 defect가 존재하는지, 어떤 object가 있는지 pre-define함.
-> pre-VCP, post-VCP를 통해 manual peompting 문제 및 class aware prompting문제는 없애고, cross modality interection을 통한 성능 향상을 봄.
introduction

- winclip에서 object를 그루핑 해서 물병을 vessel과 같이 변형하여 segmentation 해보니 mAP가 8% 상승함을 실험적으로 보았다. 이를 기반으로 최적의 prompt learning을 통해 ZSAD의 성능을 더더욱 끌어올릴 수 있을거라 생각했다.
- 프롬프팅에 앞서 기존의 CLIP 방식은 cross modality interection이 부족했다.
- manual prompt를 사용하지 않고 이미지마다 최적의 프롬프트를 생성할 수 있게 하려면 cross modality interection을 높일 필요가 있었다. fig1 참조.
Our method : 학습데이터는 VISA
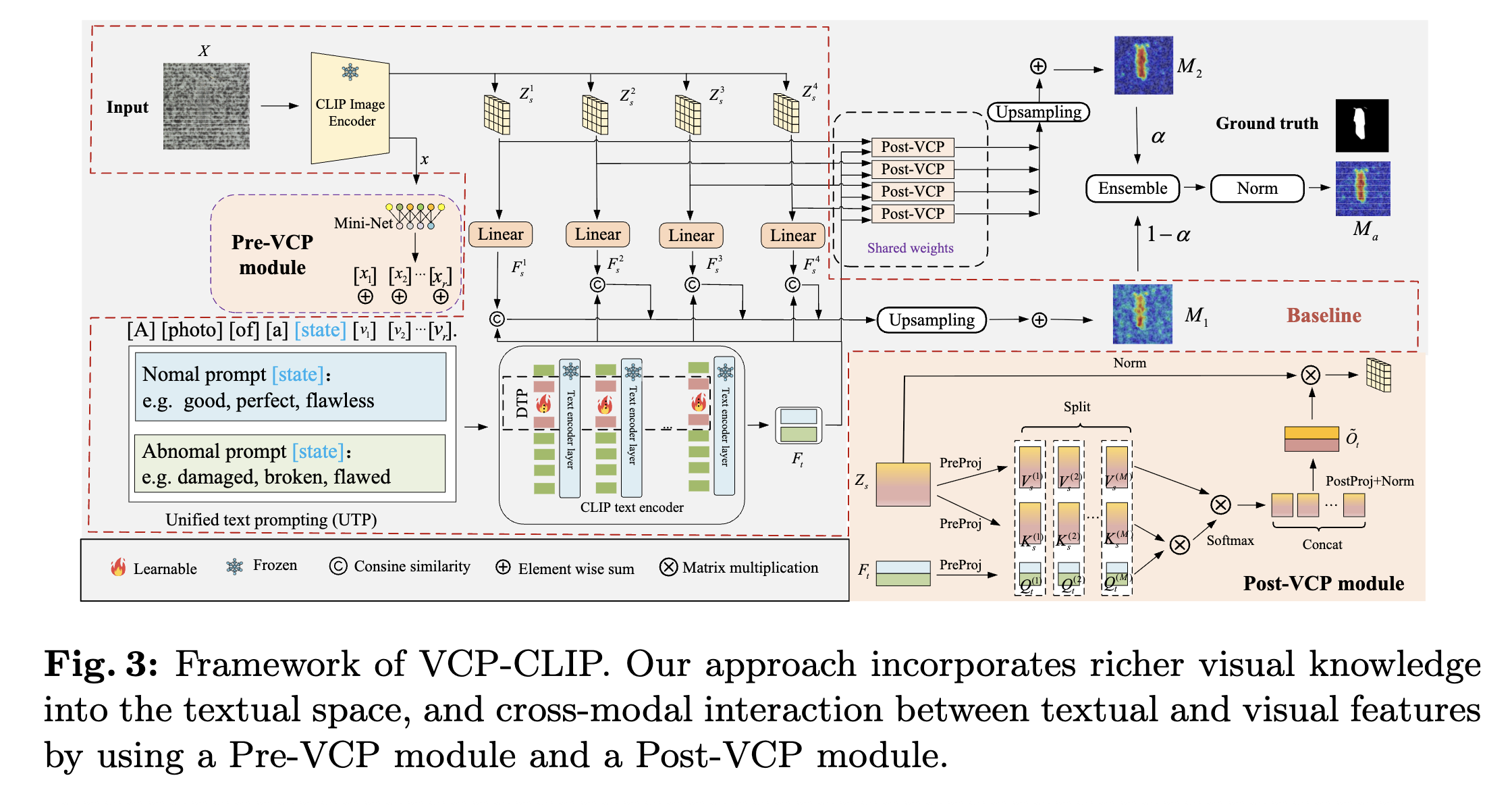
problem definition
IOU(train data, test data) = 0 인 상황에서 ZSAD가 정의 된다는데, 그냥 unseen data에 대한 inference를 수행한다고 한다.
the design of base line
unified text prompting
- image랑 text가 joint space에 매핑되어야 하는데 약간 직관적으로 쓰면 이렇게 쓸 수 있다 생각한다.
Embedding(prompt | Image), 이렇게 보면 직관적으로 이해가 쉽다.
- text prompting에서는 template&state 가 사용되는데 예시는 다음과 같다.
[SOS]a photo of a [state, good or bad][learnable param][EOS] -> 여기서 [learnable param]은 인코더에서 정의된 learnable parameter + 이미지의 CLS token이다.
- 여기서는 CLIP의 cls token을 그대로 사용해도 되는게 learnable parameter는 해당 이미지의 class 정보를 나타내게 만드는 것이 목적이기 때문이다.
- 여기서 EOS토큰을 text의 cls token으로 사용한다.
deep text prompting
- CLIP의 vision encoder에서 나온 cls token을 Conv1D layer를 거쳐 텍스트 임베딩 레이어의 learnable parameter랑 concat된다.
how to acquire the anomaly map?
- feature map과 EOS token과의 cos sim을 통해 만듦.
the design of vcp-clip?
pre-vcp module : prompt embedding에서 vision info를 고려하게 만듦
- 앞선 설명과 동일하다.
- CLIP의 vision encoder에서 나온 cls token을 Conv1D layer를 거쳐 텍스트 임베딩 레이어의 learnable parameter랑 concat된다.
- 결과적으로 [SOS]a photo of a [state, good or bad][concat(learnable param,CLS)][EOS]
post vcp module
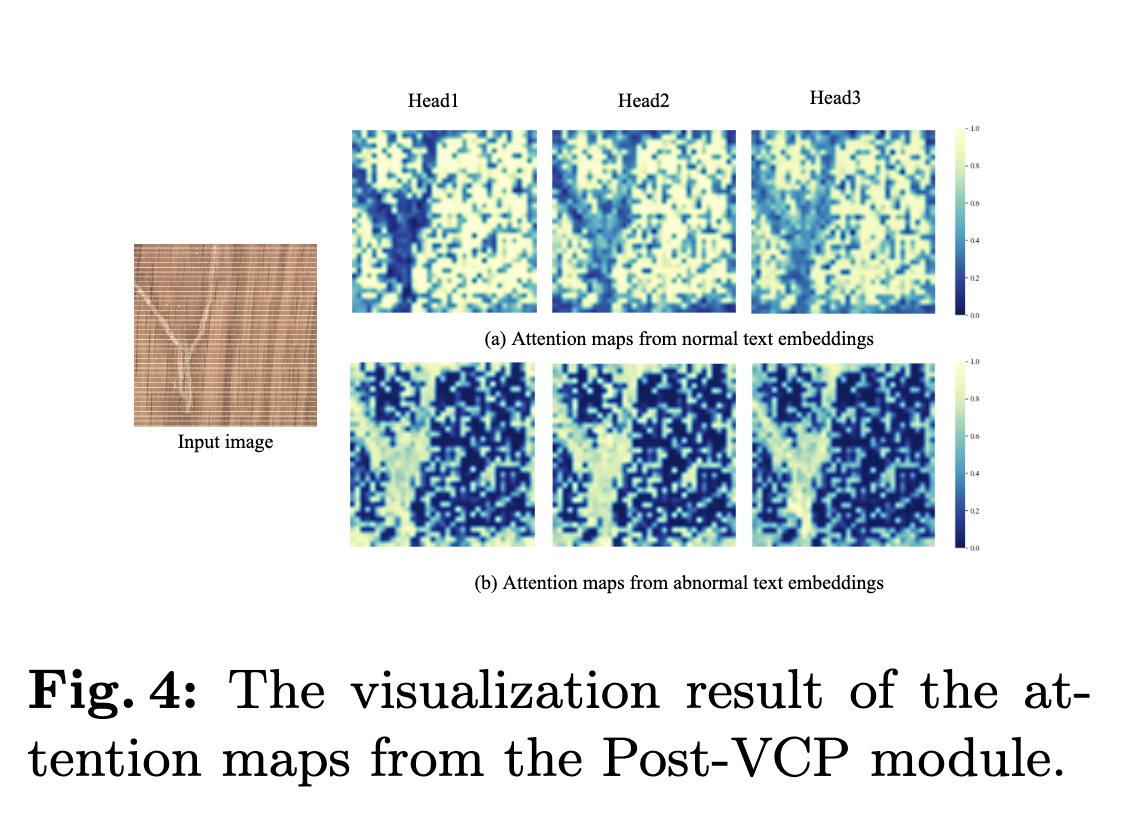
- text가 fine-grain feature의 어떤 wighted sum으로 이루어지는지 계산한다. 자세한 과정은 다음과 같다. fig4 참조.
1. P : prompt, (2,256) & I : image, (512*512,256) & 256 = embedding dim
2. P dot I.transpose =(2,512*512) -> 정상or 비정상 prompt는 이미지의 어떤 feature들의 weighted sum으로 만들어질까?
3. softmax[I dot (P dot I).Transpose] -> (512*512,2)-> (512,512,2) -> 픽셀 레벨로 이상치 값이 0~1 확률값으로 출력
training and inference
loss function
- DICE, focal loss로 0으로 bias잡는 train
inference
- train은 VISA 기반으로 진행
- normal abnormal pair at train : good/damaged
- normal abnormal pair at test : normal/abnormal ... 3개의 pair 중 하나를 사용했다고 하는데 자세한 사용은 나와있지 않음.
expriments
experimental set up
- train은 VISA
- VISA test에서는 MVTec AD로 train 하고 VISA test
compare with the state of the art
quantitutive comparision

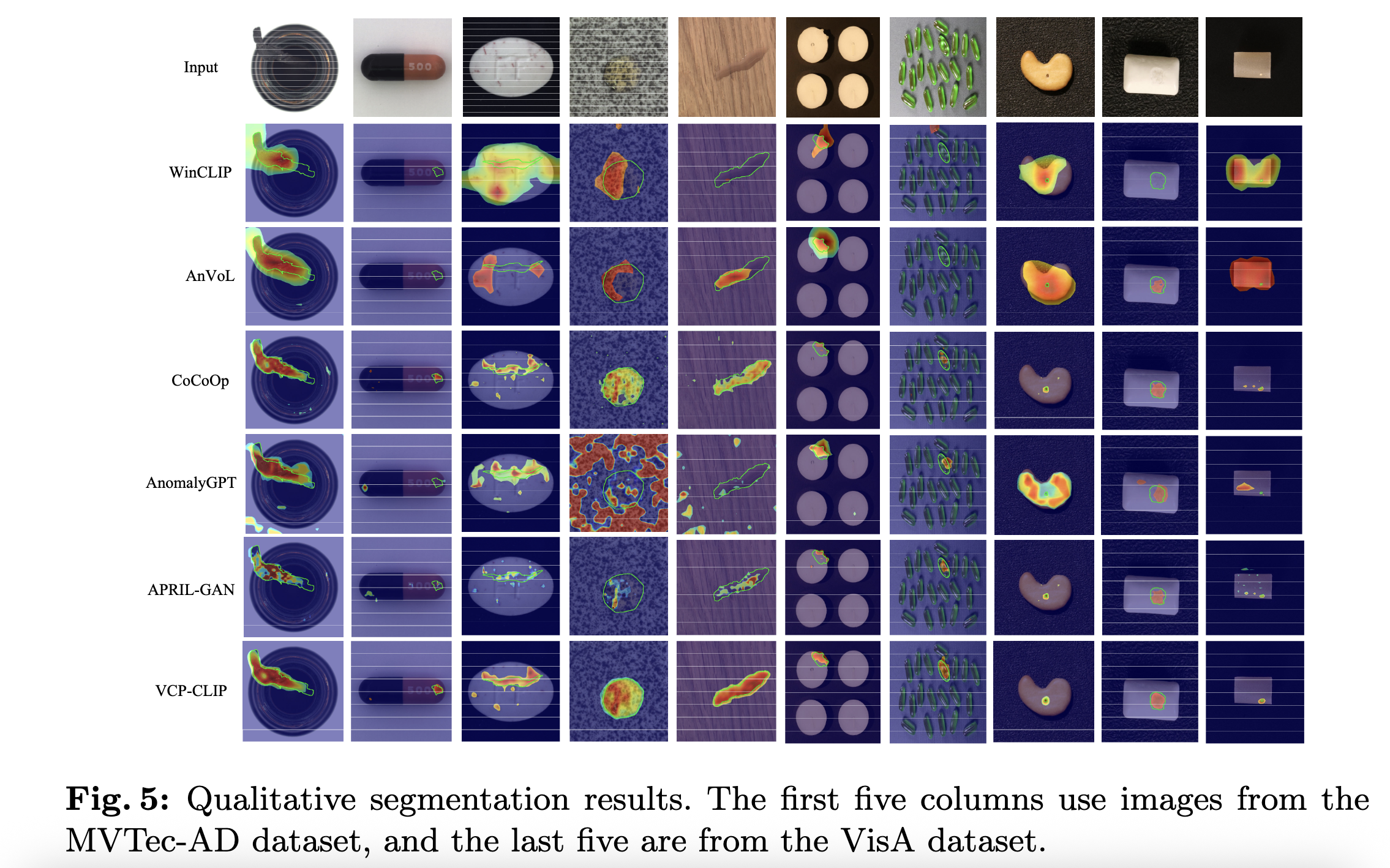
qualitative comparision
unified text prompting vs visual context prompting
same prompts during training and testing & different prompts during training and testing

pre-VPC, post-VCP를 적용하지 않은게 baseline임
fig6 : baseline이랑 동일한 state pair을 사용해서 성능 비교 표.
fig7 : state pair를 바꿔서 사용해봤는데 성능이 robust함. baseline은 성능이 떨어짐.
-> 훈련 text prompt의존성을 줄일 수 있음.
어떤 의존성? -> predefine defects가 아닌 defect는 탐지를 못하는 문제.
어떻게 해결? -> vision information이 텍스트 임베딩에 관여하고, object aware하게 prompt를 만듦
왜 object aware? -> [SOS]a photo of a [state, good or bad][concat(learnable param,CLS)][EOS] 에서 저 CLS가 vision CLS임, 즉 이미지를 보고 CLS를 동적으로 임베딩 시켜줌
