Toward Generalist Anomaly Detection via In-context Residual Learning with Few-shot Sample Prompts
why : domain adaptation없이 여러 도메인에서 non-train-few-shot-AS를 하고싶다.
what : domain adaptation을 대응하는 layer
how : domain adaptation layer를 통해 adaptation 능력을 학습하고, 이를 기반으로 few-shot-AS를 한다.
기존 모델들은 사전 학습이 필요했다. 근데 생각해보자. real-world에서 사용하려는 전제로 모델을 구성한다면, 여러 문제에 직면한다.
그중 한 가지를 특정하자면, 개인정보다 어떤 이슈로 인해 사전 학습 데이터가 없는 상황에서 어떡할것인가?
특정 데이터에 의존적인 모델을 만들지 말고, Generalist Anomaly Detection을 달성하자.
-> 하나의 모델을 만드는데 해당 모델은 어떤 anomaly-data에서든, 학습&domain adaptation없이 detect detection가능.
근데 winclip도 generalist AD가능하잖아? -> hand crafted 데이터가 필수적이잖아 이런게 안된다는거임!
일단 이걸 해결하기 위해서 그냥 image를 (real world에 존재하는 target 이미지 중 domain 상관없이 몇 장)few-shot에 사용함
learns an in-context residual learning model based on CLIP -> discriminate anomalies from normal samples by learning to identify the residuals/discrepancies between query images and a set of few-shot normal images from auxiliary data.
few-shot 이미지랑 쿼리 이미지랑의 차이를 통한 multi domain AD
근데 성능을 향상시키기 위해 사전에 학습된 모델을 통해 text랑 image랑 align 시키는 것도 좋음.
D : 서로 다른 domain data set
P : D에서 random sample, 각 도메인마다 골고루 samplinge되는 게 아님, P as subset of D
아니 프롬프트 필요 없다매, 뭐 데이터도 필요 없다면서 데이터도 필요하고 프롬프트도 필요하고, patch 단위의 CLIP을 통해 intermidiate feature에서 residual을 학습한다는데, 이거 winclip이랑 똑같잖아
암튼,
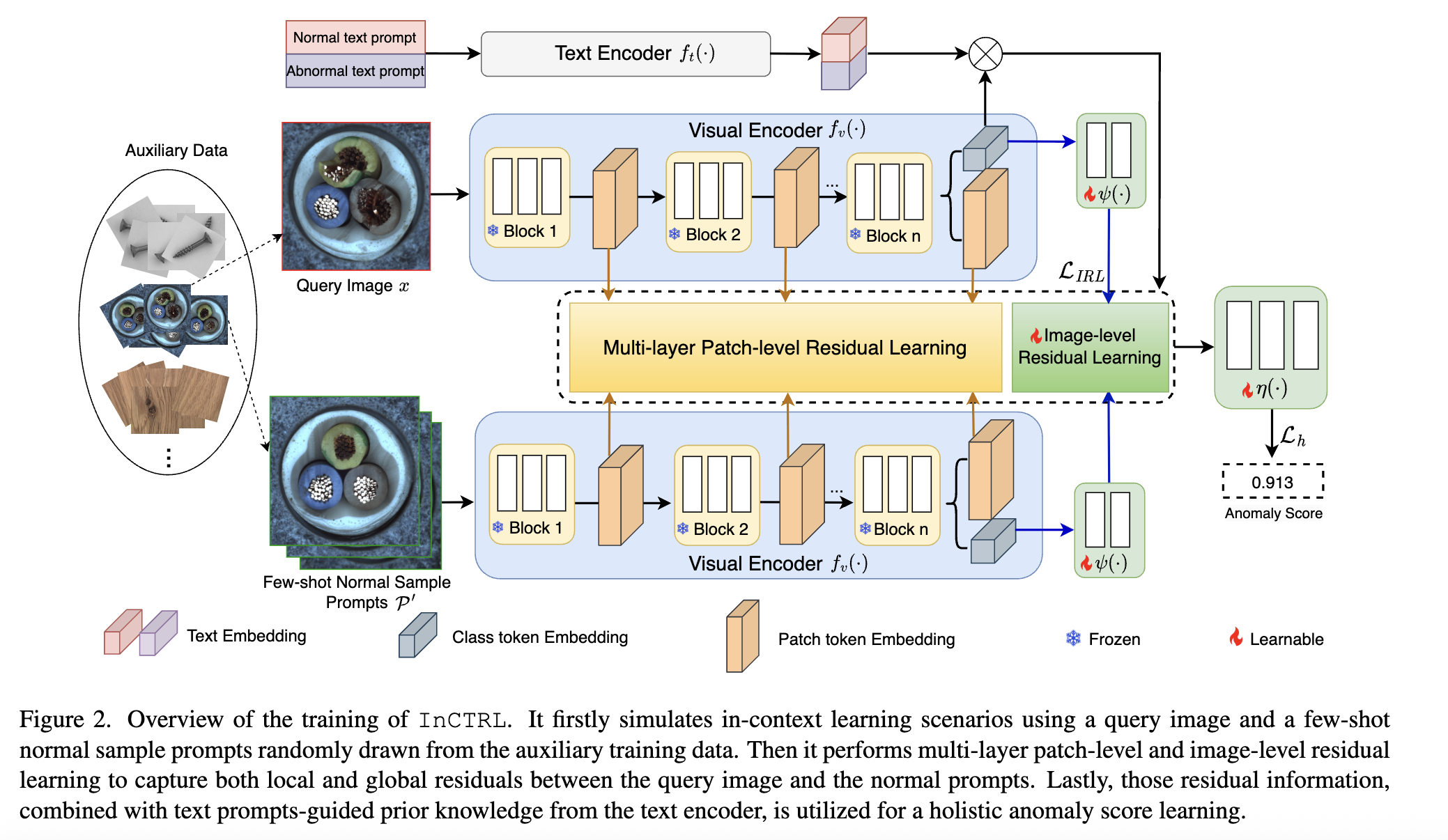
1. patch-wise, for all level features, [1-<Q, P>]| P : subset of D,를 통해 M을 만들어냄. 여기서 M : AVG([1-<Q, P>])
2. image-level에서도 anomaly score를 계사한건데 CLS 토큰을 사용할거임
- 근데 cls토큰은 anomaly score계산에 적합하지 않음, anomaly-non anomaly 이렇게 align되어있지 않음.
- adaptation layer를 적용해서 cls토큰을 AD에 적합하게 만들어줌
- 그리고 이 각각의 feature를 개별적으로 사용하는게 아니라 sample feature를 평균을 냄. 이렇게 하면 정상 샘플의 평균적인 모습을 볼 수 있음.

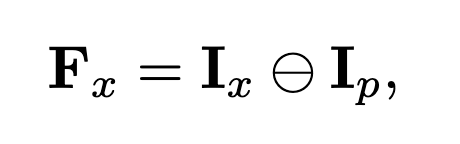

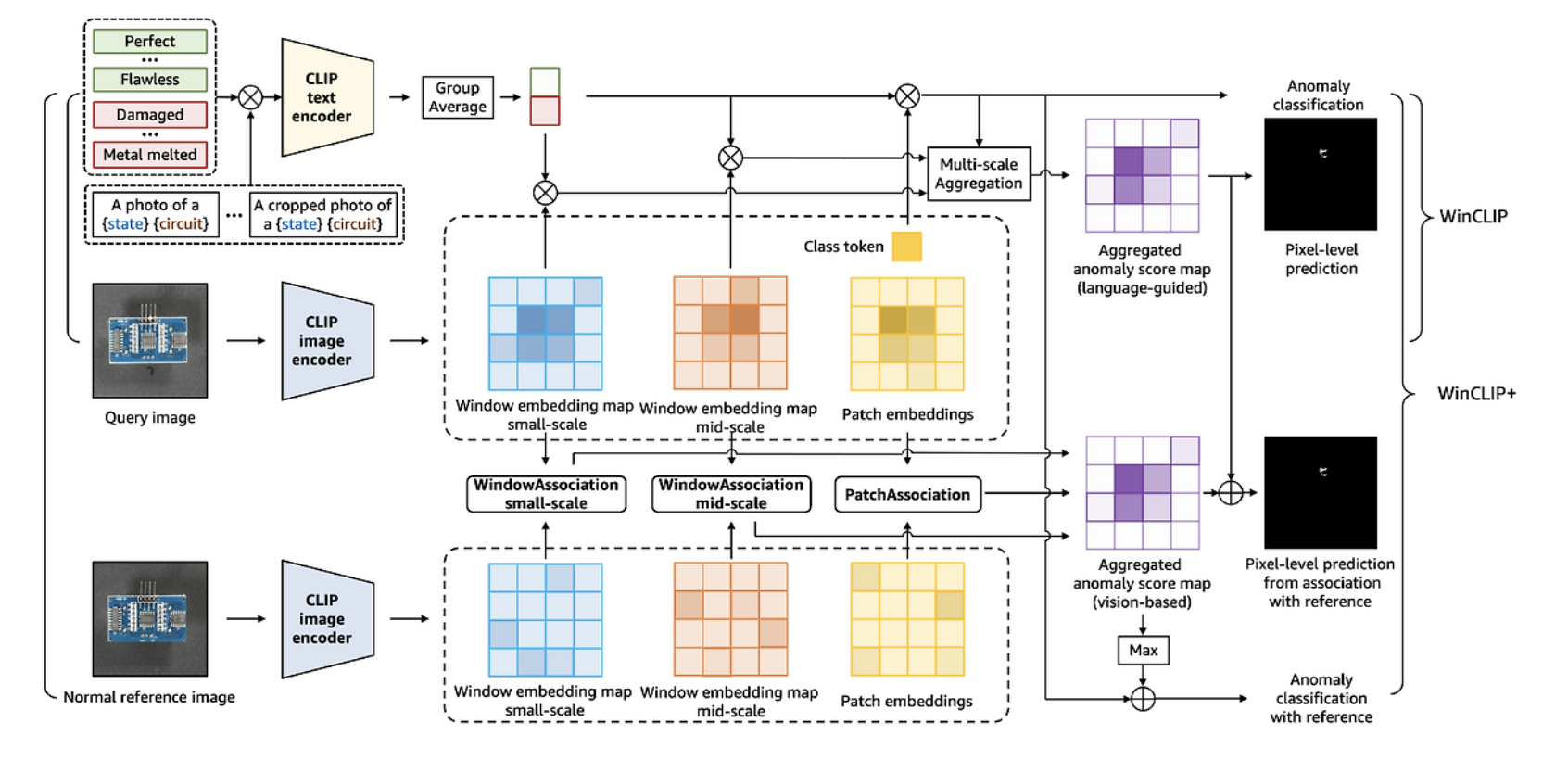
3. 이후 winCLIP 방식의 prompt를 사용해서 anomaly score를 구하는데! 잠깐만. 분명 introduction에 winclip은 text prompt 때문에 뭐 한계가 있다 라고 말했으면서 여기서는 또 프롬프트를 사용함.
-> 그냥 뭔가 label free & non-domain-adaptation GAD로 이해했는데, non-domain-adaptation GAD로 이해하자. 이정도면 말이 된다.
아무튼, winclip과의 차이점은 아니 사실 그냥 거의 똑같아보임. 그냥 어떻게 하는지를 말하자면,
이건 softmax라고 생각하면 편함. F는 프론프트의 평균인데, winclip이랑 비슷함, 양성 프롬프트의 평균과 음성 프롬프트의 평균임.
그리고 softmax하면, 양성일 확률이 나오겠지.
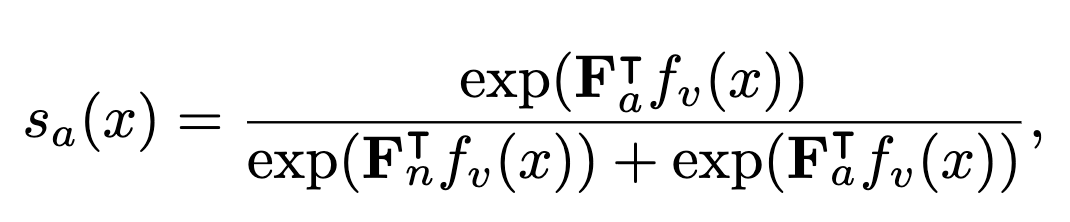
정리하면 다음과 같다.
1. winclip 구조를 사용함
2. A, B, C 데이터로 학습함
3. D, E, F 데이터로 zero-shot 테스트 함
4. 이 전 과정에서 domain-adaptation이 필요 없음. adaptation layer에서 cls-adaptation이 이미 적용되어있음
실험은 일반적인 few-shot-anomaly-segmentation을 진행. one for all, multiclass 또한 진행

한줄평 InCTRL == WinCLIP+
진짜 아이에 똑같음