AnomalyGPT: Detecting Industrial Anomalies UsingLarge Vision-Language Models
더 읽어볼 거리 :
decoder : patchcore, winclip, april-gan
요약 : 정상데이터를 이용하여, cut-paste를 이용하여 비정상 이미지를 만들고 포아송 필터를 이용하여 smoothing. 해당 데이터를 비정상 이미지로 사용한. step1. 이미지의 anomaly mask map을 만든다. step2. 이미지의 마스크맵을 prompt learner에 입력으로 넣는다. 해당 입력은 llm이 이해할 수 있게 변환된다. step3. 사용자의 text query와 combine하여 llm에 입력한다.
- step3에 사용자의 쿼리와 combine 한다 적혀있지만, 내 생각에는 concat이 더 맞는 표현 같다.
- step2에 anomaly mask map이라 적었지만 논문에서는 "pixel-level anomaly localization result" 라고 말한다. 둘 다 맞는 표현이지만, 해당 정리에서는 간단하게 mask map이라 말하겠다.

[encoder-pretrained]
- alternate training을 진행함
- image encoder를 거친 E_img in R^C_emb vector는 fed into llm after concat? combine? with anomaly mask map
- encoder의 patch level feature는 decoder에서도 사용되고 few-shot inference에서도 사용된다.
- few-shot set에서는 "normal"데이터가 frozen encoder에 들어가는데 해당 과정에사 intermidiate feature가 stroed into memory bank, 그리고 cosine similarity with query(intermidiate) which through into image encoder
-- 더 자세히 알아보면 Q ->W H C, B -> N C 를 내적 하고 max를 하니까 W H가 나오겠지
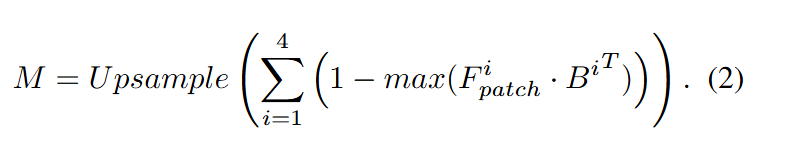
- 결론적으로 few shot이던 unsupervised던 H W의 2D mask map이 나오게 됨.
[decoder]
- unsupervised setting에서 이루어짐 위 설명과 똑같이 intermidiate features가 사용되는데 이 때는 text encoder랑 계산
[prompt learner]
- 1. mask map을 n,Cemb로 변환, 2.learnable base prompt embedding을 준비함, 3. image encoder

decoder랑 prompt learner를 학습시키기 위해서 CE, FL, DL을 도입함
cross_et_loss : target text랑 모델이 만드는걸 이용해서 로스 구함, prompt learner가 잘 번역하는지 학습
focal : 정상 픽셀이 많아서 0만 출력할텐데 local loss로 1도 좀 출력하게 만들어
dice : M에 대한 segmentation loss임